LLVM是什么?当我第一次思考这个问题时,我发现自己缺乏O-LLVM (Obfuscator-LLVM)的知识。我需要利用O-LLVM项目来开发一个工具来混淆Android的Native C/ C++的代码,同时研究虚拟机保护技术。事实上,O-LLVM是源自LLVM项目。它使用LLVM的来混淆代码生成过程的中间表达(Intermediate Representation),然后将其送到后端,最后后端生成目标的机器码。
让我们看一下LLVM在维基百科的定义:
LLVM编译器的基础设施项目是“”模块化、可重用的编译器和工具链技术的集合”,用于开发编译器前端和后端。
LLVM的历史

2000年,Chris Lattner进入伊利诺伊大学香槟分校攻读硕士学位。他是个超级大学霸,平均绩点达到4分,在学习之余,他还游历了美国许多名胜古迹,并反复阅读《编译者之书:原理、技术和工具》(Compilers: Principles, Techniques)。LLVM项目是在他的导师Vikram Adve的指导下开始的。在他的学习生活中,他的核心研究领域是编译器,他的硕士论文《LLVM:一个多阶段优化的编译器架构》(LLVM: an infrastructure for multi-stage optimisation),在这篇论文中,他提出了一种使用低级表示形式,但同时能表达高级信息的虚拟指令。他将其称为低层虚拟机,这是LLVM项目的原型(LLVM是低层虚拟机的缩写,Low Level Virtual Machine)。
他敏锐地意识到当时编译器(或者称为解释器)存在着几个问题,于是他决心解决它们。
1.1 当时的编译器存在的问题
从2000年12月开始,LLVM被设计为一组具有定义良好接口的可重用库[LA04]。当时,开放源码编程语言实现被设计成实现特殊用途的工具,通常被当做一个整体来执行。例如,重用GCC静态编译器的语法分析器模块来进行静态分析或重构就非常困难。虽然脚本语言通常可以将运行时状态(runtime)和解释器(interpreter)嵌入到更大的应用程序中,但是这个运行时状态是包含或排除一个整体代码块的条件下构建的。没有重用代码片段的方法,而且在跨语言的项目实现时难以共享代码。
除了编译器本身的组成之外,围绕流行的编程语言实现的社区通常是两极分化的:要么是传统的静态编译器(如GCC、Free Pascal和FreeBASIC),要么是以解释器或JIT(Just-in-time)编译器的形式提供运行时编译器(runtime compiler)。但同时支持这两种功能的语言实现是非常少见的,即使它们都支持,通常也很少共享代码。
| 存在的问题 | 优化的方向 |
|---|---|
| 中间表达形态(IR - Intermediate Representation)不能兼具通用性和强表达力 | 重新设计一种IR语言既包含低级信息也包含高级信息 |
| 整体化、高内聚的设计架构 | 改用模块化的设计模型 |
| 难以用SDK和库的形式来重用 | 设计一种完美的调用机制 |
表格:LLVM最初的优化的方向
1.2 LLVM都做了些什么?
LLVM重新设计了一种中间表达式(IR)。这种新的LLVM虚拟指令提供了低层表示(紧凑表示、各种可用的转换等)的好处,还提供了高级信息,以支持在链接时和链接后主动进行过程间优化。特别是,该系统的设计目的是支持运行时优化,甚至在机器的空闲时间进行优化。
总之,LLVM最初是作为一项基础设施研究而进行开发的,用于研究静态和动态编程语言的动态编译技术。
在Chrise Lattner博士期间,他进一步使用GCC作为前端进行语义分析,生成中间格式(IF - Intermediate Format),然后使用LLVM完成优化和代码生成的工作。至此,Lattner作为一名编译工程师,开始在编译器开发的社区里小有名气。
1.3 LLVM的潜在价值被苹果公司挖掘
因此,在2005年,苹果公司雇佣了Lattner,并为他组建了一个团队,为实现苹果系统中的各种用途而开发LLVM系统。LLVM是苹果最新的macOS和iOS开发工具的一个组成部分。自2013年以来,索尼一直在PlayStation 4游戏机的软件开发工具包(SDK)中使用LLVM的Clang作为前端编译器。
LLVM最初是低级虚拟机的首字母缩写(Low Level Virtual Machine)。为了避免混淆,官方已经废弃掉这个称呼了,因为LLVM已经发展成为一个覆盖面更广的项目了,与大多数开发人员所认为的虚拟机几乎没有关系。现在,LLVM已经发展为一个包含LLVM中间表达式(IR)、LLVM调试器、C++标准库实现(完全支持C++ 11和C++ 14)等的大项目。目前LLVM由LLVM基金会管理。
如今,LLVM一个是比其他编译器更好的编译器工具链,与GCC相比,它具有以下优点:
- 在某些平台中编译要比GCC快得多,例如,调试模式下编译Objective-C时,LLVM比GCC快3倍。
- 在生成抽象语法树(AST - Abstract Syntax Tree)时,占用的内存仅为GCC的1/5。
- LLVM调试的调试信息表达更精准、更容易易分析和阅读。
- LLVM被设计成一个模块化库,更容易嵌入IDE或进行重用。
- LLVM很灵活,并且比GCC更容易扩展。
LLVM是用C++编写的,用于编译时、链接时、运行时和“空闲时”优化用任意编程语言编写的程序。最初只是为了编译C和C++,可是LLVM的语言无关架构设计已经催生了各种各样的前端:LLVM支持的语言包括ActionScript, Ada, C#, Common Lisp, Crystal, CUDA, D, Delphi, Fortran, Graphical G Programming Language, Halide, Haskell, Java bytecode, Julia, Kotlin, Lua, Objective-C, OpenGL Shading Language, Pony, Python, R, Ruby, Rust, Scala, Swift, and Xojo。
我读过Chris Lattner在《开源软件的架构》(The Architecture of Open Source Applications)一书中所写的的文章:LLVM。接下来,我将做一些从中摘录一些关键性的笔记来讲解LLVM。
2 编译器的三段式架构
传统静态编译器(与大多数C编译器一样)最流行的设计是三段式设计,其主要组件是前端(Frontend)、优化器(Optimiser)和后端(Backend)。前端解析源代码,检查错误,并构建一个特定语言的抽象语法树(AST)来表示输入代码。AST可以选择性地转换为中间表达式,以便用于优化器。之后再经过优化器和后端,最后生成能在机器上运行的机器码。

优化器负责执行各种各样的转换,以尝试改进代码的运行时间,例如消除冗余代码,这个过程通常是与前后端无关的。后端(也称为代码生成器)将代码映射到目标指令集。除了生成正确的代码外,它还可以根据所支持的体系结构的特点,来生成适应该架构的优质代码。编译器后端常见的部分包括指令选择、寄存器分配和指令调度。
这个模型同样适用于解释器和JIT编译器。Java虚拟机(JVM - Java Virtual Machine)也是这个模型的实现,它使用Java字节码作为前端和优化器之间的接口。
2.1 该模型的优点
这种设计模式的过人之处,体现在当编译器决定支持多种源语言或目标体系结构时。如果编译器在其优化器中使用公共代码表示,那么可以为任何可以编译到它的语言编写前端,也可以为任何可以从它编译的目标编写后端,如下图所示。
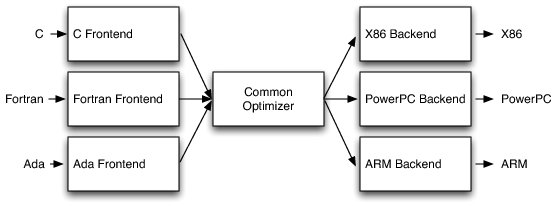
使用这种设计模式有三个优点:
可重用好。 由于前端和后端是分离的,当移植一个新的语言源(例如Algol或BASIC)时,只需要实现一个新的前端,而现有的优化器和后端保持不变即可。
享受丰富的开发者资源。 这种设计意味着它支持不止一种源语言和目标(例如Intel cpu、ARM、MIPS),从而为更广泛的程序员提供服务。如果有更多的开发人员参与到这个项目中,那么就会有更多高质量的代码产生,这自然会对编译器带来更多的增强和改进。
有利于分工。 实现前端所需的技能与优化器和后端所需的技能不同。将它们分开可以使“前端人员”更容易地增强和维护他们的编译器部分。虽然这是一个社交问题,而不是技术问题,但在实践中它非常重要,尤其是对于希望尽可能减少贡献障碍的开源项目。
2.2 目前的编程语言是如何实现编译过程的?
虽然编译器的三段式设计的好处是显然的,并且被写进了我们的教科书里,但实际上它几乎从未完全的实现过。纵观开源语言实现,回到在LLVM项目的启动之初,你会发现Perl、Python、Ruby和Java的实现没有共享代码。此外,像Glasgow Haskell Compiler (GHC)和FreeBASIC这样的项目虽然可以重定向到多个不同的CPU,但是它们的实现非常依赖于某一种特定的编程语言(也就是它们所支持那种语言)。各种用于特殊用途的编译器技术被用于实现JIT编译器,用以实现图像处理、正则表达式、显卡驱动程序,或者被用于其他需要密集型CPU工作的领域。
这个模型有三个主要的成功案例:
Java虚拟机和 .NET 虚拟机。 首先是Java虚拟机和.NET虚拟机。这两个系统都提供了JIT编译器、运行时支持和定义优良的字节码格式。这意味着任何可以编译成字节码格式的语言(有几十种格式)都可以利用优化器、JIT、运行时(runtime)。权衡的结果是,Java和.NET在实现运行时(runtime)的时候,几乎没有提供灵活性:它们都强制JIT编译、垃圾收集机制和使用非常特殊的对象模型。当编译与此模型不匹配的语言(如C语言、LLJVM项目)时,这会导致性能低下。
翻译成C代码。 第二个成功案例可能是最不幸的,但也是重用编译器技术最流行的方法:将输入源翻译成C代码(或其他语言),并用现有的C编译器进行处理。这允许重用优化器和代码生成器,提供良好的灵活性,控制了运行时,并且前端实现人员非常容易理解、实现和维护。但不幸的是,这样做会阻止异常处理的有效实现,是得调试的体验变得糟糕,降低编译速度,并且对于需要保证尾调用(或着C语言不支持的其他特性)的语言可能会有问题。
GCC编译器。 此模型的最后一个成功实现是GCC。GCC支持许多前端和后端,并拥有一个活跃而广泛的开发者社区。GCC作为一个C编译器有着悠久的历史,它支持多个目标,并同时支持多语言实现。随着时间的推移,GCC社区正在向更纯粹而简洁的设计靠近。从GCC 4.4开始,它为优化器提供了一个新的表示(称为“GIMPLE元组”),与以前的表达形式相比,与前端的分离程度更高。此外,它的Fortran前端和Ada前端使用一中更简洁的AST。
这三种成功案例虽然看上去不错,但实质上它们还是存在着较大的局限性,因为它们被设计为单一而整体的程序。例如,我们不可能将GCC嵌入到其他应用程序中、将GCC用作运行时/JIT编译器,或者在不引入大部分编译器的情况下提取和重用GCC的代码片段。想要使用GCC的C++前端来生成文档、建立代码索引、重构代码或者制作静态分析工具,我们必须将GCC作为一个整体应用程序来使用。我们需要以XML的形式发送的信息,或者编写插件来将外部代码注入GCC进程中。
GCC不能作为可重用的库的原因有很多,包括大量使用全局变量、弱的常量、设计不佳的数据结构、不断扩展的代码库,以及使用宏来阻止将基本代码一次编译成支持多对前端/目标的能力。然而,最难解决的问题源自其早期设计时固有架构问题。具体来说,GCC存在分层问题和抽象泄漏的问题:后端遍历前端AST来生成调试信息,前端生成后端数据结构,而整个编译器又依赖于命令行接口设置的全局数据结构。