1 概述
Why Data Mining?
What Is Data Mining?
Extraction of interesting (non-trivial, implicit, previously unknown and potentially useful) patterns or knowledge from huge amount of data
Alternative names
Knowledge discovery (mining) in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting, business intelligence, etc.
- A Multi-Dimensional View of Data Mining
- Data to be mined: Knowledge discovery in database (KDD) …….
Knowledge to be mined (or: Data mining functions): Characterization, discrimination, association, classification, clustering, trend/deviation, outlier analysis, etc.
Techniques utilized: ML, stastics
- Applications adapted: in Business Intelligence
- What Kinds of Data Can Be Mined?
Database-oriented data sets and applications
Advanced data sets and advanced applications
- What Kinds of Patterns Can Be Mined?
Data Mining Function: (1) Generalization (2) Association and Correlation Analysis (3) Classification (4) Cluster Analysis (5) Outlier Analysis
Time and Ordering: Sequential Pattern, Trend and Evolution Analysis
Structure and Network Analysis
Evaluation of Knowledge
- What Kinds of Technologies Are Used?
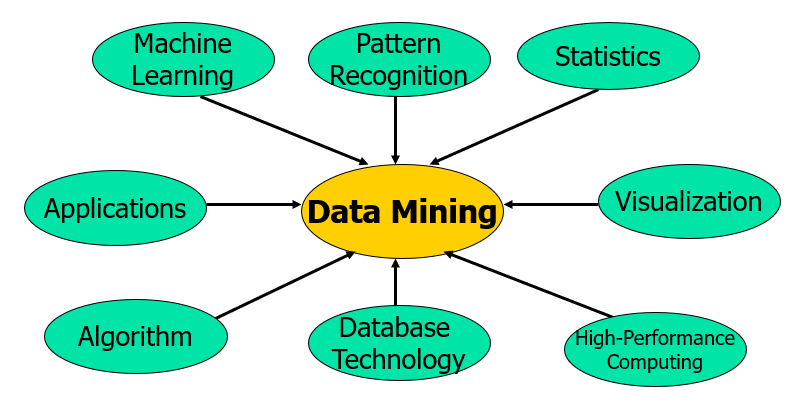
- What Kinds of Applications Are Targeted?
Web page analysis: from web page classification, clustering to PageRank & HITS algorithms
Collaborative analysis & recommender systems
Basket data analysis to targeted marketing
Biological and medical data analysis: classification, cluster analysis (microarray data analysis), biological sequence analysis, biological network analysis
Data mining and software engineering (e.g., IEEE Computer, Aug. 2009 issue)
- Major Issues in Data Mining
Mining Methodology, User Interaction, Efficiency and Scalability, Diversity of data types, Data mining and society
A Brief History of Data Mining and Data Mining Society
Summary
2 数据
Data Objects and Attribute Types
Basic Statistical Descriptions of Data
Measuring Data Similarity and Dissimilarity
- Heuristic
- Minkowski-form
- Weighted-Mean-Variance (WMV)
- Nonparametric test statistics
- $x^2$ (Chi Square)
- Kolmogorov-Smirnov (KS)
- Cramer/von Mises (CvM)
- Information-theory divergences
- Kullback-Liebler (KL)
- Jeffrey-divergence (JD)
- Ground distance measures
- Histogram intersection
- Quadratic form (QF)
- Earth Movers Distance (EMD)
Example: cosine similarity
Example: Dissimilarity between Binary variables => asymmetric / symmetric binary
Example: Minkowski Distance => 跟我们学的Lp-norm是一样的
Summary
3 模式挖掘
《使用Apriori算法和FP-growth算法进行关联分析》,有代码示例:https://www.cnblogs.com/qwertWZ/p/4510857.html
3 集成方法
《Adaboost - 新的角度理解权值更新策略》推导Adaboost的权重更新公式:https://blog.csdn.net/dream_angel_z/article/details/52348135