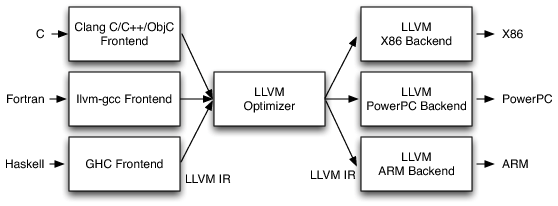
图1.LLVM的三段式架构
根据我们对传统编译器三段式设计的了解,源代码通常需要经过六个部分,最后生成目标的机器码:
- 词法分析。 词法分析将字符序列转换为记号的序列。执行词法分析的程序包括了词法分析器、记号序列化生成器和扫描器,不过扫描器常常作为词法分析器的第一阶段。
- 语法分析。 分析符合一定语法规则的一串符号。它通常会生成一个语法树(或称为AST - Abstract Syntax tree),用于表示记号之间的语法关系。
- 语义分析。 通过语法分析的解析后,这个过程将从源代码中收集必要的语义信息。它通常包括类型检查,或者确保在使用之前声明了变量,这在EBNF范式中是不可能描述的,因此在语法分析阶段不容易检测到。
- 中间表达式(IR)生成。 代码在这个阶段会转换为中间表示式(IR),这是一种中立的语言,与源语言(前端)和机器(后端)无关。
- 优化中间表达式。 IR代码常常会有冗余和死代码的情况出现,而优化器可以处理这些问题以获得更优异的性能。
- 生成目标代码。 最后后端会生成在目标机器上运行的机器码,我们也将其称之为目标代码。
LLVM结构也遵循这种由6部分的设计。如图1所示,是LLVM的三段式设计,而图2展示了三个阶段是如何被分为六个部分的。还有值得注意的是。一方面,狭义的LLVM仅包括优化器和后端,也就是负责IR的优化和目标代码的生成;另一方面,广义的LLVM是指所有的三个阶段、完整工具链,以及一整套的SDK编译器开发技术体系。我们通常称它为LLVM集合。
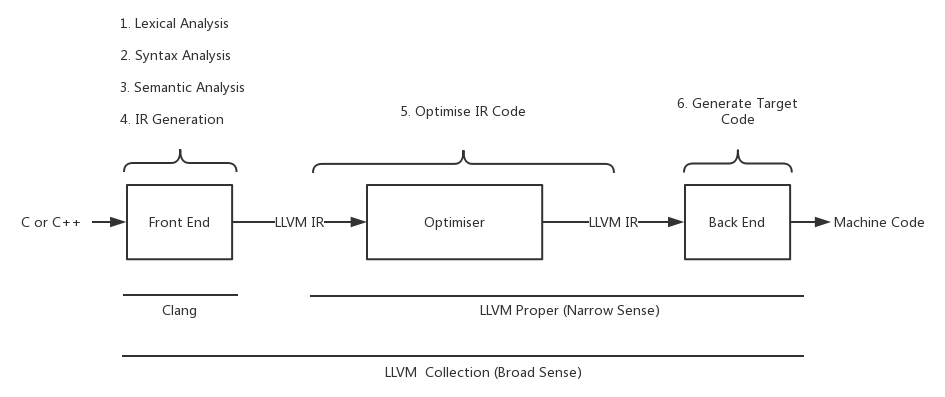
图2.将LLVM拆解成六部分
1 进一步地阐述LLVM模型
如图所示,新的IR语言是通过优化器连接前端和后端的桥梁。前端将把不同的源语言转换成中立的IR表达式,它们将在优化器中经过若干的模块优化后,尽可能达到完美的状态。然后将优化后的代码移送到后端,为不同的目标生成机器码。
1.1 如何写LLVM的中间表达式(IR)来进行优化
为了让您对优化如何工作有一些直观的了解,有必要浏览一些示例。因为有许多不同类型的编译器优化,所以很难提供一个能解决任意问题的方法。但是,大部分的优化遵循一个简单的三部分结构:
- 寻找要转换的模式。
- 验证匹配实例的转换是否安全/正确。
- 进行转换,更新代码。
最简单的优化是算术恒等式的模式匹配,比如:对于任意的整数 X,我们会有
X-X= 0X-0=X(X*2)-X=X
首先就是上述这些表达式在LLVM IR中是如何表示的,以下是一些例子:1
2
3
4
5
6
7
8⋮ ⋮ ⋮
%example1 = sub i32 %a, %a
⋮ ⋮ ⋮
%example2 = sub i32 %b, 0
⋮ ⋮ ⋮
%tmp = mul i32 %c, 2
%example3 = sub i32 %tmp, %c
⋮ ⋮ ⋮
对于这些类型的窥孔转换(peephole transformations),LLVM提供了一个指令简化接口,作为各种其他高级转换的工具。这些特殊的变换位于SimplifySubInst函数中,看起来像这样:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// X - 0 -> X
if (match(Op1, m_Zero()))
return Op0;
// X - X -> 0
if (Op0 == Op1)
return Constant::getNullValue(Op0->getType());
// (X*2) - X -> X
if (match(Op0, m_Mul(m_Specific(Op1), m_ConstantInt<2>())))
return Op1;
…
return 0; // Nothing matched, return null to indicate no transformation.
在这段代码中,Op0和Op1是整数减指令的左右操作数,需要注意的是,这些恒等式不一定适用于IEEE浮点数。LLVM是用C++实现的,而与Objective Caml等函数性语言相比,C++的模式匹配能力并不是特别有名,但它提供了一个通用性良好的模板系统,允许我们实现类似的功能。match函数和m\_函数允许我们在LLVM IR代码上执行声明式模式匹配操作。例如,m\_Specific谓词只有在乘法的左边与Op1相同时才匹配。
这三种情况都是模式匹配的,如果可以,函数返回替换,如果不可替换,则返回空指针。这个函数的调用者(SimplifyInstruction)是一个分发器(dispatcher),它打开指令操作码,将其分派到每个操作码的helper函数中。它是通过各种优化调用的。一个简单的驱动程序是这样的:1
2
3for (BasicBlock::iterator I = BB->begin(), E = BB->end(); I != E; ++I)
if (Value *V = SimplifyInstruction(I))
I->replaceAllUsesWith(V);
这段代码只是循环遍历块中的每条指令,检查它们是否简化了。当SimplifyInstruction返回非空时,即说明存在未简化的指令,它将使用replaceAllUsesWith方法使用简单的形式来替代代码中的任何内容。
1.2 LLVM中间表达式(IR)具有表达的完备性
特别是,LLVM IR是被指定的、优化器的唯一接口。这意味着,要为LLVM编写前端,只需要知道LLVM IR是什么、它是如何工作的以及它所期望的不变量是什么。由于LLVM IR具有优秀的文本形式,因此可以构建一个前端,将LLVM IR输出为文本,然后通过Unix管道将其发送到你选择的一系列优化器和代码生成器中。
这可能会令你感到惊讶,但这实际上是LLVM的一个非常新颖的特性,也是它在广泛的应用程序中获得成功的主要原因之一。即使是非常成功且架构相对良好的GCC编译器也没有这个特性:它的GIMPLE中间层表示不是一个自包含的表示。举一个简单的例子,当GCC代码生成器发出DWARF调试信息时,它返回并遍历源代码层的“树”。GIMPLE本身对代码中的操作使用元组(tuple)表示,但是(至少在GCC 4.5中)仍然将操作数表示为对源代码层的树的引用。
这意味着前端作者需要知道并生成GCC的树数据结构,以及GIMPLE来编写GCC前端。GCC后端也有类似的问题,所以他们还需要了解RTL后端是如何工作的。最后,GCC没有办法以文本形式输出“表示代码的所有内容”,也没有办法读写GIMPLE(以及构成代码表示形式的相关数据结构)。结果是,GCC的实验相对困难,因此前端相对较少。
1.3 LLVM是库的集合
在设计了LLVM IR之后,LLVM的下一个最重要的方面就是将LLVM设计成一系列的库,而不是像GCC那样的单一命令行编译器,或者像JVM或.NET虚拟机那样的不透明虚拟机。LLVM是一种基础设施,是一组有用的编译器技术,可以用于处理特定的问题(比如构建C编译器,或者在特殊效果管道中构建优化器)。虽然这是它最强大的功能之一,但也是它最不为人知的设计要点之一。

看上面的图,优化器是LLVM的中间过程。它读取LLVM IR,处理它,然后输出LLVM IR。我们当然希望它能执行得更快,但是应该怎么做呢?在LLVM(与许多其他编译器一样)中,优化器被设计为由若干优化模块的集合,每个优化模块(pass) 都能读入IR,完成一些任务后,输出优化后的IR。常见优化模块的例子是内联优化,它会将函数体替换为调用点(call sites),还有,可以将表达式重新组合(expression reassociation)、移动循环不变代码(loop-invariant code motion)等等。根据优化级别的不同,可以调用不同的优化模块:例如,Clang编译器使用-O0(无优化状态)参数进行编译时不调用pass,在使用-O3时将会调用67个pass来进行IR的优化(从LLVM 2.8开始)。
每个LLVM的pass都被写成C++类,该类间接地继承自Pass类。它们大多数都是写在一个.cpp文件里的,而子类的Pass类在一个匿名名称空间中定义,这使得某一种子类限定在定义它的文件中,是私有的。为了使pass有用,文件外部的代码必须能够获得它,因此需要从文件中导出一个能够被外部调用的函数。下面是一个简单的例子:1
2
3
4
5
6
7
8
9
10
11
12namespace {
class Hello : public FunctionPass {
public:
// Print out the names of functions in the LLVM IR being optimized.
virtual bool runOnFunction(Function &F) {
cerr << "Hello: " << F.getName() << "\n";
return false;
}
};
}
FunctionPass *createHelloPass() { return new Hello(); }
如前所述,LLVM优化器提供了几十种不同的优化模块,每种优化模块都以类似的风格编写。这些优化模块被编译成一个或多个.o文件,然后将其构建到一系列存档库中(在Unix系统上是.a文件)。这些库提供了各式各样的分析和转换功能,并且优化模块之间是尽可能松散耦合的:它们应该相互独立的,或者说,如果某一模块需要依赖于其他的模块来完成工作,则应该显式地声明它们之间的依赖关系。当给定一系列要运行的优化模块后,LLVM PassManager会加载这些依赖信息来实现这些依赖项的调用,使得优化模块能够正常运行。
虽然库和抽象功能很好,但它们实际上不能解决所有问题。有趣的是,当有人想要构建一个可以从编译器技术中获益的新工具时,可能是一个用于图像处理语言的JIT编译器。这个JIT编译器的实现者考虑到了一些条件:例如,图像处理语言可能对编译时延迟非常敏感,并且具有一些特定的语言属性,而这些属性对于优化性能非常重要。
基于库的LLVM优化器的设计,允许我们指定优化模块的执行顺序,以及选择对图像处理领域有意义的那些模块:如果所有内容都定义成一个大函数,那么浪费时间在内联上就没有意义了;如果指针很少,别名分析(alias anlysis)和内存优化(memory optimization)就不值得费心。然而,尽管我们尽了最大的努力,LLVM并不能神奇地解决所有优化问题!由于优化模块的子系统是模块化的,而PassManager本身对优化模块的内部机制一无所知,所以实现人员可以自由地实现自己特定于语言的优化模块,以弥补LLVM优化器中的不足,或者明确地提供特定于语言的优化机会。下图展示了我们一个假想的XYZ图像处理系统的简单例子:
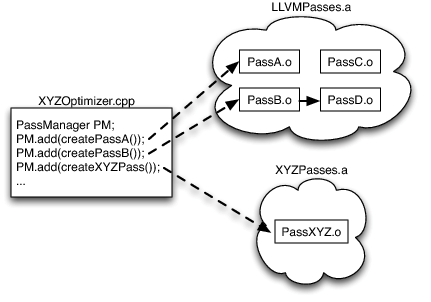
一旦选择了一组优化(并且为代码生成器做出了类似的决策),图像处理编译器就内置到可执行库或动态库中。因为对LLVM的优化模块的唯一引用是在每个.o文件中定义的简单的create函数,而优化器又是在.a文件的档案库中的,因此只有实际使用的优化模块才能链接到最终应用程序,而不是整个LLVM优化器。在上面的示例中,由于有对PassA和PassB的引用,所以它们将被链接进来。因为PassB使用了PassD来做一些分析,所以PassD被链接进来。但是,由于没有使用PassC(以及许多其他优化),所以它的代码没有链接到进来。
这就是基于库的LLVM的强大之处。这种简单的设计方法允许LLVM提供大量的功能,其中一些功能可能只有特定的用户才会用到,而对于不需要这些功能的人来说,不调用就是了。相比之下,传统的编译器优化器是作为紧密连接的代码块构建的,这使得子模块的提取、代码分析和加速运行变得更加困难。而使用LLVM,你可以单独弄明白优化器,而不需要知道整个系统是如何组合在一起的。
这种基于库的设计也是许多人误解LLVM是什么的原因:LLVM库有很多功能,但它们自己什么也不做。调用库(例如Clang C编译器)的设计人员可以决定如何最好地使用这些代码块。这种细致的分层、分类和重视子模块的能力,正是LLVM优化器可以在不同的环境中,用于如此广泛的应用程序的原因。而且,虽然LLVM提供了JIT编译功能,但并不意味着每个客户机都使用它。
1.4 可重定向的LLVM代码生成器的设计
LLVM代码生成器负责将LLVM IR转换为目标特定的机器码。一方面来说,代码生成器的工作是为给定的目标生成尽可能好的机器码。理想情况下,一个代码生成器应该对应一个目标,但另一方面,每个目标的代码生成器需要解决的问题又具有某种相似性。例如,每个目标都需要为寄存器分配值,尽管每个目标都有不同的寄存器文件,但是我们应该能设计一种通用的的算法。
与优化器中的方法类似,LLVM的代码生成器(code generator)将代码的生成分成若干的模块(pass)——指令选择、寄存器分配、调度、代码布局优化和统一分发——并提供许多默认运行的内置模块(builtin passes)。然后,代码生成器的开发者可以自主地选择默认模块,重写模块,或者可以根据需要,自行编写用于生成特定目标代码的模块。例如,x86的后端使用寄存器减压调度器,因为它只有很少的寄存器,但是PowerPC后端使用延迟优化调度器,因为它有很多寄存器。x86后端使用自定义模块来处理x87浮点堆栈,ARM后端使用自定义模块来将常量池(constant pool islands)放置在需要的函数中。这种灵活性允许目标开发者(target author)生成优秀的代码,而不必为他们的目标从头开始编写整个代码生成器。
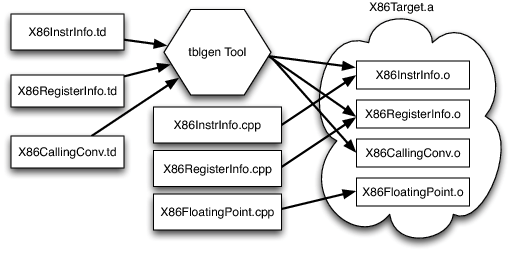
“混合和匹配”方法允许目标作者选择对其体系结构有意义的内容,并允许在不同目标之间重用大量的代码。这带来了另一个挑战:每个共享组件都需要能够以通用的方式推断出目标特定的属性。例如,共享的寄存器分配器需要知道每个目标的寄存器文件,以及指令与其寄存器操作数之间存在的约束关系。LLVM对此的解决方案是为每个目标提供一个目标描述,这是一种具有声明属性的特定域的语言(也就是一组.td文件),由tblgen工具负责处理。简化后的x86目标的构建过程如下图所示:
.td文件所支持的不同子系统允许目标开发者构建目标的不同部分。例如,x86后端定义了一个register类,它包含所有32位寄存器,命名为”GR32”(在.td文件中,目标的定义都是大写的)像这样:1
2
3def GR32 : RegisterClass<[i32], 32,
[EAX, ECX, EDX, ESI, EDI, EBX, EBP, ESP,
R8D, R9D, R10D, R11D, R14D, R15D, R12D, R13D]> { … }
这个定义说这个类中的寄存器可以保存32位整数值(“i32”),使用32位对齐,具有指定的16个寄存器(在.td文件的其他地方定义),而且还会有更多的信息来指定寄存器的分配顺序和其他事情。使用这个定义后,特定的指令可以引用它,将它作为运算对象。例如,“补全32位寄存器”的指令定义为:1
2
3
4
5let Constraints = "$src = $dst" in
def NOT32r : I<0xF7, MRM2r,
(outs GR32:$dst), (ins GR32:$src),
"not{l}\t$dst",
[(set GR32:$dst, (not GR32:$src))]>;
这个定义说NOT32r是一条指令(使用Itblgen类来表示):
- 指定了编码信息(
0 xf7 MRM2r) - 定义了输出是32位寄存器
$dst,而输入也是32位寄存器$src,GR32是上一段代码定义的寄存器对象,它规定了哪些计寄存器作为运算对象是合法的 - 指定指令的汇编语法,使用
{}语法同时处理美国电话电报公司(AT&T)和英特尔(Intel)的语法 - 说明指令的效果,并提供最后一行的匹配模式
- 第一行中的”let”约束告诉寄存器分配器,必须将输入和输出寄存器分配给相同的物理寄存器。
这个定义是对指令的一种非常密集的描述,公共LLVM代码可以利用这些信息(通过tblgen工具)做很多事情。这一个定义足以使指令选择器通过对编译器的输入IR代码进行模式匹配来生成这条指令。它还告诉寄存器分配器如何处理它,足以将指令编码和解码为机器字节码(machine code bytes),并足以以文本形式将指令解析和打印出来。这些功能允许一个x86架构的机器支持从目标描述中生成一个独立的x86汇编程序(它是”gas” GNU汇编程序的一个替代)和反汇编程序,并处理JIT指令的编码。
除了提供有用的功能之外,从相同的“事实”生成多个信息片段还有其他好处。这种方法使得汇编程序和反汇编程序在汇编语法或二进制编码上彼此不一致的问题得到解决。它还使目标描述(target description)易于测试:指令的编码可以进行单元测试,而不需要涉及整个代码生成器。
尽管我们的期望将td文件设计成一种很好的声明形式,以获得尽可能多的目标信息,但我们仍然不能解决所有的问题。目前而言,我们还是需要目标机器的开发者编写一些C++的支持函数(support routines),并实现任何目标机器都会用到的特定模块(比如X86FloatingPoint.cpp,它处理x87浮点堆栈)。随着LLVM不断增加对新目标机器的支持,增加可以在.td中表示的目标数量变得越来越重要,我们将通过继续增强.td文件的表达能力来实现。相信我们,随着时间的推移,在LLVM中编写目标将会变得越来越容易。
2 深入讨论模块化设计
模块化不仅是一种优雅的设计,还为LLVM库的使用者提供了一些有趣的功能。这些功能均源于LLVM提供的功能,但是使用者可以自行决定如何使用它。
2.1 模块化设计给LLVM带来的一些有意思的能力
如前所述,LLVM IR可以有效地序列化为二进制的形式(被称为LLVM bitcode),或者从二进制的形式进行反序列化回LLVM IR。由于LLVM IR是自包含(self-contained)的,而且序列化是一个无损过程,所以我们可以进行部分编译,将进展保存到磁盘,然后在将来的某个时候继续工作。该特性提供了许多有趣的功能,包括对链接间和安装时优化的支持,这两个功能都延迟了从“编译时”生成代码的时间。
链接时间优化(LTO - Link-TIme Optimization)解决了编译器传统上只看到一个翻译单元的问题(例如,一个.c文件及它的所有头文件),因此不能跨文件边界进行优化,比如内联(inlining)。像Clang这样的LLVM编译器使用-flto或-O4的命令行选项来支持这一点。此选项指示编译器向.o文件发送LLVM bitcode,而不是写一个本机对象文件(native object file),并延迟代码在链接时间(link time)的生成,如下图所示:

具体情况取决于您所使用的操作系统,但重要的是链接器检测到.o文件中有LLVM bitcode而不是本机对象文件。当它看到这一点时,它将所有bitcode文件读入内存,将它们链接在一起,然后在一个集合体(over the aggregate)上运行LLVM优化器。由于优化器现在可以一次性扫描很大一部分代码,因此它可以内联、传导常量、进行死代码消除,以及跨文件边界执行更多操作。虽然许多现代编译器都支持LTO,但是它们中的大多数(例如GCC、Open64、Intel编译器等)都是通过代价高昂而缓慢的序列化过程来实现的。在LLVM中,LTO自然地脱离了系统的设计,并且可以跨不同的源语言(与许多其他编译器不同)工作,因为IR是一门真正的中立语言(即与前后端无关)。
安装时优化的概念是延迟代码生成,甚至比链接时间还要晚,直到安装时间,如下图所示。安装时间是一个非常有趣的时间(在软件装入一个盒子、下载、上传到移动设备等情况下),因为这时候你才能知道目标设备的特性。例如,在x86家族中,有各种各样的芯片和特性。通过延迟指令选择、调度和代码生成的其他方面,你可以为应用程序最终运行的特定硬件生成最佳的代码。

2.2 可以对优化器进行单元测试
编译器非常复杂,而质量很重要,所以测试是至关重要的。例如,在修复了导致优化器崩溃的bug之后,应该添加一个回归测试,以确保它不会再次发生。传统的测试方法是编写一个编译器中运行.c文件,并用一个测试工具来验证编译器是否崩溃。例如,这就是GCC测试套件使用的方法。
这种方法的问题是,编译器由许多不同的子系统组成,甚至优化器中有许多不同的模块(pass),所有这些子系统都可能会在输入代码与产生Bug的节点之间修改过代码。如果在前端或更早的优化器中发生了更改,测试用例会难以测试它应该测试的内容。
通过使用带有模块化优化器的文本形式的LLVM IR,LLVM测试套件注重回归测试,这些测试可以从磁盘加载LLVM IR,只运行特定的一个模块(pass),验证预期的行为。除了崩溃之外,更复杂的行为测试还需要验证是否确实执行了优化。下面是一个简单的测试用例,它检查常量传播(constant propagation)通过是否使用了add指令:1
2
3
4
5
6
7; RUN: opt < %s -constprop -S | FileCheck %s
define i32 @test() {
%A = add i32 4, 5
ret i32 %A
; CHECK: @test()
; CHECK: ret i32 9
}
RUN那一行的代码,指定了要执行的命令:在本例中,是opt和FileCheck命令行工具。opt程序是一个简单的LLVM模块管理器(pass manager)的封装,它链接所有的标准模块(并且可以动态加载包含其他模块的插件),并将它们通过命令行显示出来。FileCheck工具验证它的标准输入是否匹配一系列CHECK指令。在本例中,这个简单的测试验证constprop模块是否将4和5之和折叠(folding)为9。
虽然这看起来是一个非常简单的例子,但是通过编写.c文件来测试是非常困难的:前端在解析时经常进行常量折叠(costant folding),因此编写代码来进行后续的常量折叠优化是非常困难和脆弱的。因为我们可以将LLVM IR作为文本加载,并送入我们感兴趣的特定优化模块,然后将结果作为另一个文本文件转储出去,所以测试我们真正想要的东西非常简单,既可以用于回归测试,也可以用于特性测试。
2.3 根据错误点自动减少测试用例
当在LLVM库的编译器或其他客户机中发现Bug时,修复它的第一步是编写一个能重现问题的测试用例。一旦你有了一个测试用例,最好将其最小化到重现问题的最小示例,并将其缩小到问题发生的LLVM部分。例如,定位到发生故障的那个优化模块。虽然,最终你将知道如何实现这一点,但是这个过程是冗长的、手工的,对于编译器生成不正确的代码但不会崩溃的情况尤其痛苦。
LLVM BugPoint工具使用了IR序列化和LLVM的模块化设计来自动化这个过程。例如,给定一个输入.ll文件或.bc文件,还有一个导致优化器崩溃的模块列表,BugPoint会将输入逐步简化测试用例,直至最小化,最后判断出哪个优化器有错误。然后,输出简化后的测试用例和用于重现失败的opt命令。它通过使用类似于“增量调试”(delta debugging)的技术来减少输入和优化器模块列表(optimizer pass list),从而发现这一点。因为BugPoint知道LLVM IR的结构,所以它不会像标准的”delta”命令行工具那样,浪费时间生成要输入到优化器的无效IR。
在更复杂的错误编译情况下,可以指定输入、代码生成器信息,指明需要执行的命令行和输出的引用(reference output)。BugPoint将首先确定问题是由于优化器还是代码生成器造成的,然后重复地将测试用例划分为两个部分:一个发送到“已知的好”组件中(第一部分),另一个发送到“已知的错误”组件中(第二部分)。通过迭代,将会有越来越多的代码从第二部分中被移除,最终我们会得到一个最小化的测试用例。
BugPoint是一个非常简单的工具,它在LLVM的整个生命周期中节省了无数的本需要人工去减少测试用例的时间。没有其他开源编译器拥有类似的强大工具,因为LLVM依赖于定义良好的中间表示(IR)。但BugPoint并不是完美的,还需要不断地重写来改进它。它的历史可以追溯到2002年,通常只有当某人发现了一个非常棘手的bug,而现有工具又不能很好地处理时,它才会得到改进。Bugpoint随着时间的推移而发展,在没有一致的设计或所有者的情况下增加了新特性(比如JIT调试)。