ML-HW1 PDF
Update on October 4, 2019: ML-HW1 Solution PDF
Question 1

According to the known condition, make $x_0=1$ i.e. add a column with 1 in matrix $X$:
The OLS solution:
Question 2
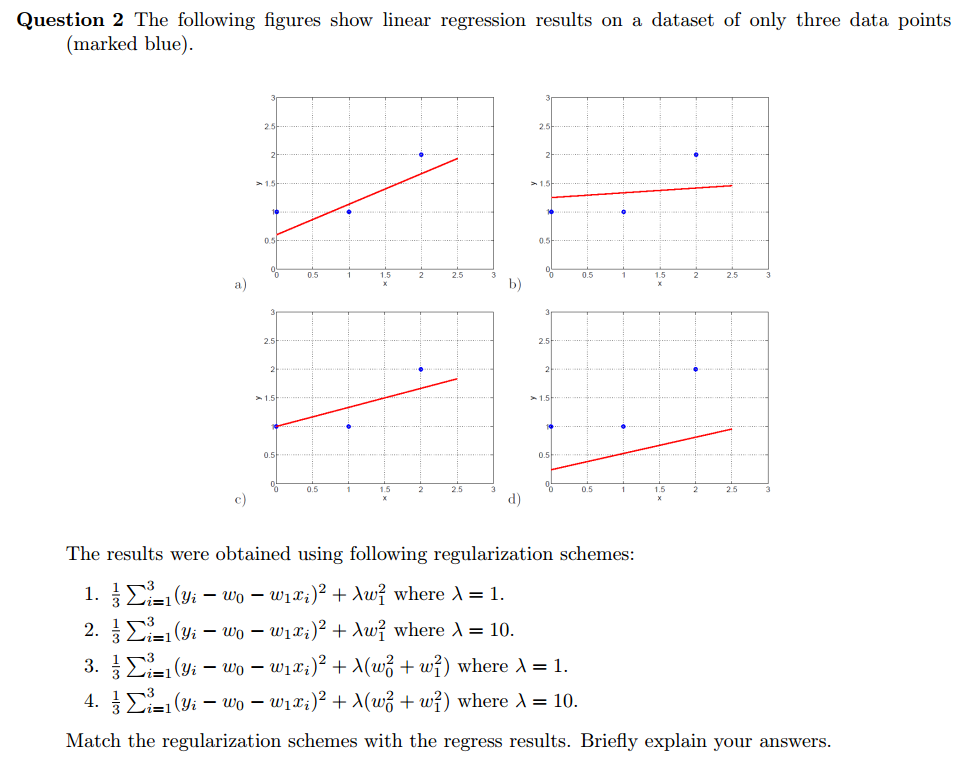
- $\frac{1}{3} \sum_{i=1}^3 (y_i-\omega_0-\omega_1x_i)^2 + \lambda \omega_1^2$ where $\lambda=1$ —-> (c)
- $\frac{1}{3} \sum_{i=1}^3 (y_i-\omega_0-\omega_1x_i)^2 + \lambda \omega_1^2$ where $\lambda=10$ —-> (b)
- $\frac{1}{3} \sum_{i=1}^3 (y_i-\omega_0-w_1x_i)^2 + \lambda (\omega_0^2+\omega_1^2)$ where $\lambda=1$ —-> (a)
- $\frac{1}{3} \sum_{i=1}^3 (y_i-\omega_0-\omega_1x_i)^2 + \lambda (\omega_0^2+\omega_1^2)$ where $\lambda=10$ —-> (d)
Explanation If we give the linear regression line an equation $y=kx+b$ then the $\omega_0$ is $b$ and the $\omega_1$ is $k$. The (c) line has lower slope because the $1\cdot \omega_1^2$ will make slope smaller. However too big $\lambda = 10$ will cause nearly no slope in the (b) line. If we add $w_0^2$ to the regularization, it causes both $b$ and $k$ decay. Compared to (1), the answer would be (a) line which has smaller $b$. Obviously, (4) will match (d) line because both $b$ and $k$ are small and the line is underfitting.
Question 3


Like Question 1, writing down the matrix $X$ and $y$:
Use batch gradient descent algorithm, get the parameter $\omega$ freshing formula
Suppose $\omega_0 = -2$, $\omega_1 = 1$ and $\omega_2 = 1$ initially and $\alpha = 0.1$. So we can calculate
Similarly, we can calculated
Use sigmoid function
The class distribution is [0, 0, 0, 1] so the training error = 0%
Question 4

use raw features
If we use only raw features to classify, we would find that it’s a linear-inseparable question. This is because that we cannot find a surface to distinguish the positive and the negative. I use \textit{numpy} to help me calculate the batch gradient descent (BGD) process.
1 | X4 = np.array([[1,0,0], |
No matter how many iterations I run, the minimum error only achieves 1. After 100 iterations,
1 | weight = [-0.3395675 0.28609699 0.28609699] |
After 1,000 iterations,
1 | weight = [-2.23876505e-07 1.88743639e-07 1.88743639e-07] |
add an additional feature
However, if we add an additional feature, it’s equivalent to that projecting features from 2D to 3D. This makes the problem become linear-separable. Using the following code, after doing approximately 130 iterations, we can get a model having 0 trainning error (minimum training error).
1 | X5 = np.array([[1,0,0, 0], |
The weight and y_predict after 130 iterations,
1 | weight = [ 0.0819811 -0.97091908 -0.97091908 3.39687673] |
Question 5

If predicted value $\sigma({\omega}^T {x}_i)$ is smaller than the actual value $y_i$, there is reason to increase $w_j$. The increment is proportional to $x_{i,1}$. If predicted value $\sigma({\omega}^T {x}_i)$ is larger than the actual value $y_i$, there is reason to decrease $w_j$. The decrement is proportional to $x_{i,1}$.
However, the question has already supposed the feature $x_1$ is binary whose value is unbalanced. The zero value of $x_1$ keeps the $w_1$ from \textit{learning} features from the example with LABEL 0. Otherwise, the $\omega_1$ would adjust according to both two classes. Therefore, this rule will force the model to fit example with a small number of training examples with LABEL 1 ( special feature in training set ). This causes \textbf{overfitting}.
Then adding the regularization constant is able to \textbf{reduce overfitting}. It helps the model not to learn too much from the training set. In the update rule, the $-\lambda \omega_1$ is independent, not influenced by the feature $x_1$.