Lecture Plan
- Classification review/introduction
- Neural networks introduction
- Named Entity Recognition
- Binary true vs. corrupted word window classification
- Matrix calculus introduction
提示:这对一些人而言将是困难的一周,课后需要阅读提供的资料。
1 Classification setup and notation
通常我们有由样本组成的训练数据集
$x_i$ 是输入,例如单词(索引或是向量),句子,文档等等,维度为 $d$
$y_i$ 是我们尝试预测的标签( $C$ 个类别中的一个),例如:
- 类别:感情,命名实体,购买/售出的决定
- 其他单词
- 之后:多词序列的
Classification intuition
训练数据: $\left\{x_{i}, y_{i}\right\}_{i=1}^{N}$
简单的说明情况
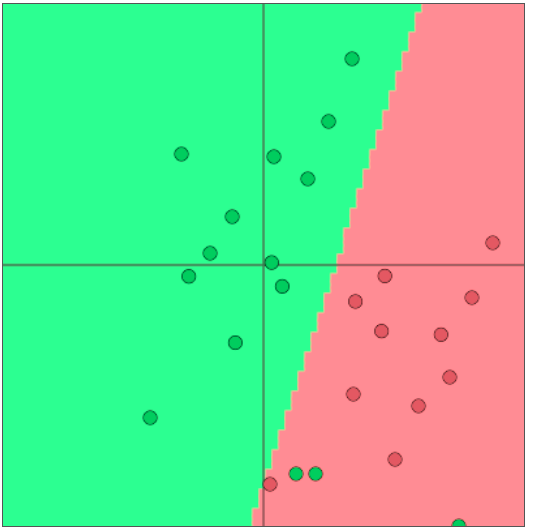
- 固定的二维单词向量分类
- 使用softmax/logistic regression
- 线性决策边界
传统的机器学习/统计学方法:假设 $x_i$ 是固定的,训练 softmax/logistic 回归的权重 $W \in \mathbb{R}^{C \times d}$ 来决定决定边界(超平面)
方法:对每个 $x$ ,预测
我们可以将预测函数分为两个步骤:
- 将 $W$ 的 $y^{th}$ 行和 $x$ 中的对应行相乘,然后求和,得到分数
计算所有的 $f_c, for \ c=1,\dots,C$
- 使用softmax函数获得归一化的概率
Training with softmax and cross-entropy loss
对于每个训练样本 $(x,y)$ ,我们的目标是最大化正确类 $y$ 的概率,或者我们可以最小化该类的负对数概率
Background: What is “cross entropy” loss/error?
- 交叉熵”的概念来源于信息论,衡量两个分布之间的差异
- 令真实概率分布为 $p$
- 令我们计算的模型概率为 $q$
- 交叉熵为假设 groud truth (or true or gold or target)的概率分布在正确的类上为1,在其他任何地方为0:$p = [0,…,0,1,0,…0]$
因为 $p$ 是独热向量,所以唯一剩下的项是真实类的负对数概率
Classification over a full dataset
在整个数据集 $\left\{x_{i}, y_{i}\right\}_{i=1}^{N}$ 上的交叉熵损失函数,是所有样本的交叉熵的均值
我们不使用
我们使用矩阵来表示 $f$
Traditional ML optimization
- 一般机器学习的参数 $\theta$ 通常只由W的列组成因此,我们只通过以下方式更新决策边界
2 Neural Network Classifiers
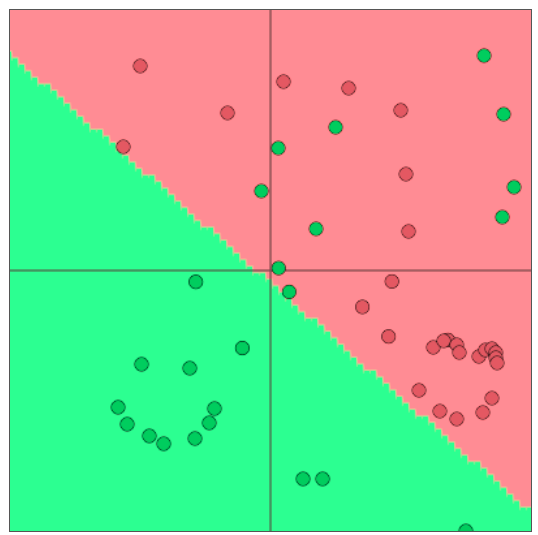
- 单独使用Softmax(≈logistic回归)并不十分强大
- Softmax只给出线性决策边界
- 这可能是相当有限的,当问题很复杂时是无用的
- 纠正这些错误不是很酷吗?
Neural Nets for the Win!
神经网络可以学习更复杂的函数和非线性决策边界
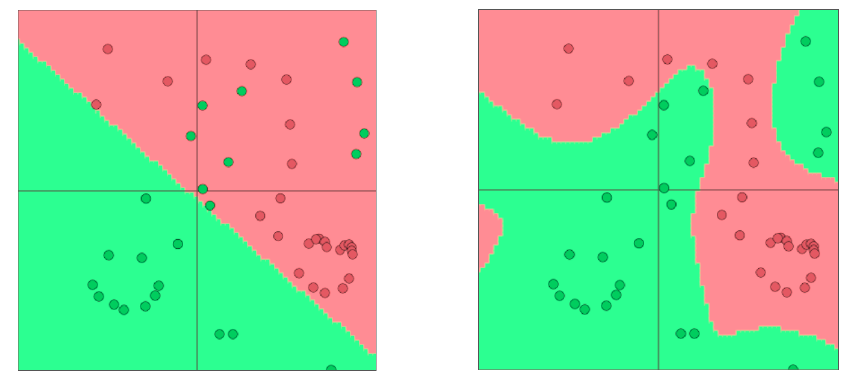
更高级的分类需要
- 词向量
- 更深层次的深层神经网络
Classification difference with word vectors
一般在NLP深度学习中
- 我们学习了矩阵 $W$ 和词向量 $x$
- 我们学习传统参数和表示
- 词向量是对独热向量的重新表示——在中间层向量空间中移动它们——以便使用(线性)softmax分类器通过 $x = Le$ 层进行分类
- 即将词向量理解为一层神经网络,输入单词的独热向量并获得单词的词向量表示,并且我们需要对其进行更新。其中,$Vd$ 是数量很大的参数
Neural computation
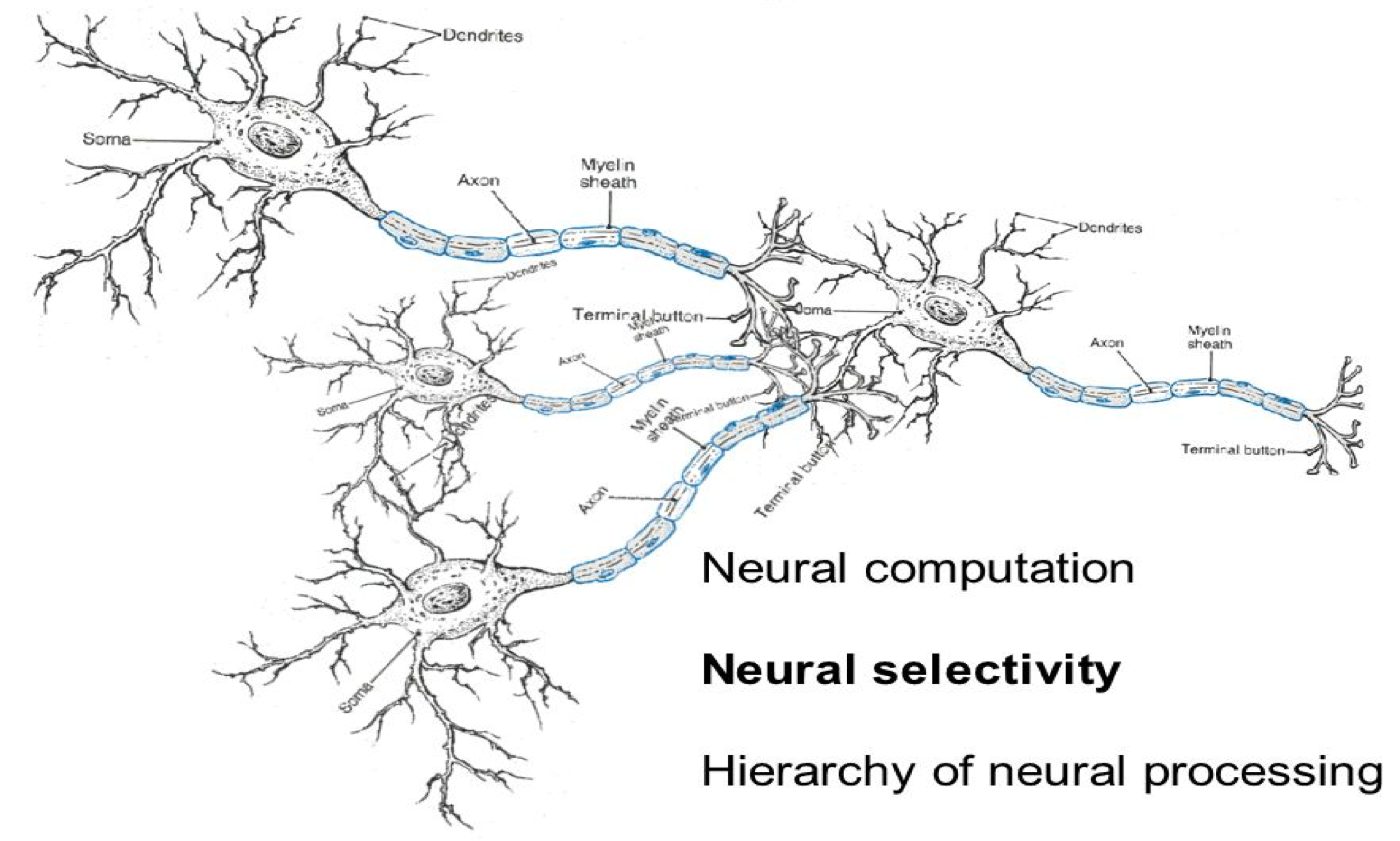
An artificial neuron
- 神经网络领域有属于自己的一些术语
- 但如果你了解 softmax 模型是如何工作的,那么你就可以很容易地理解神经元的操作
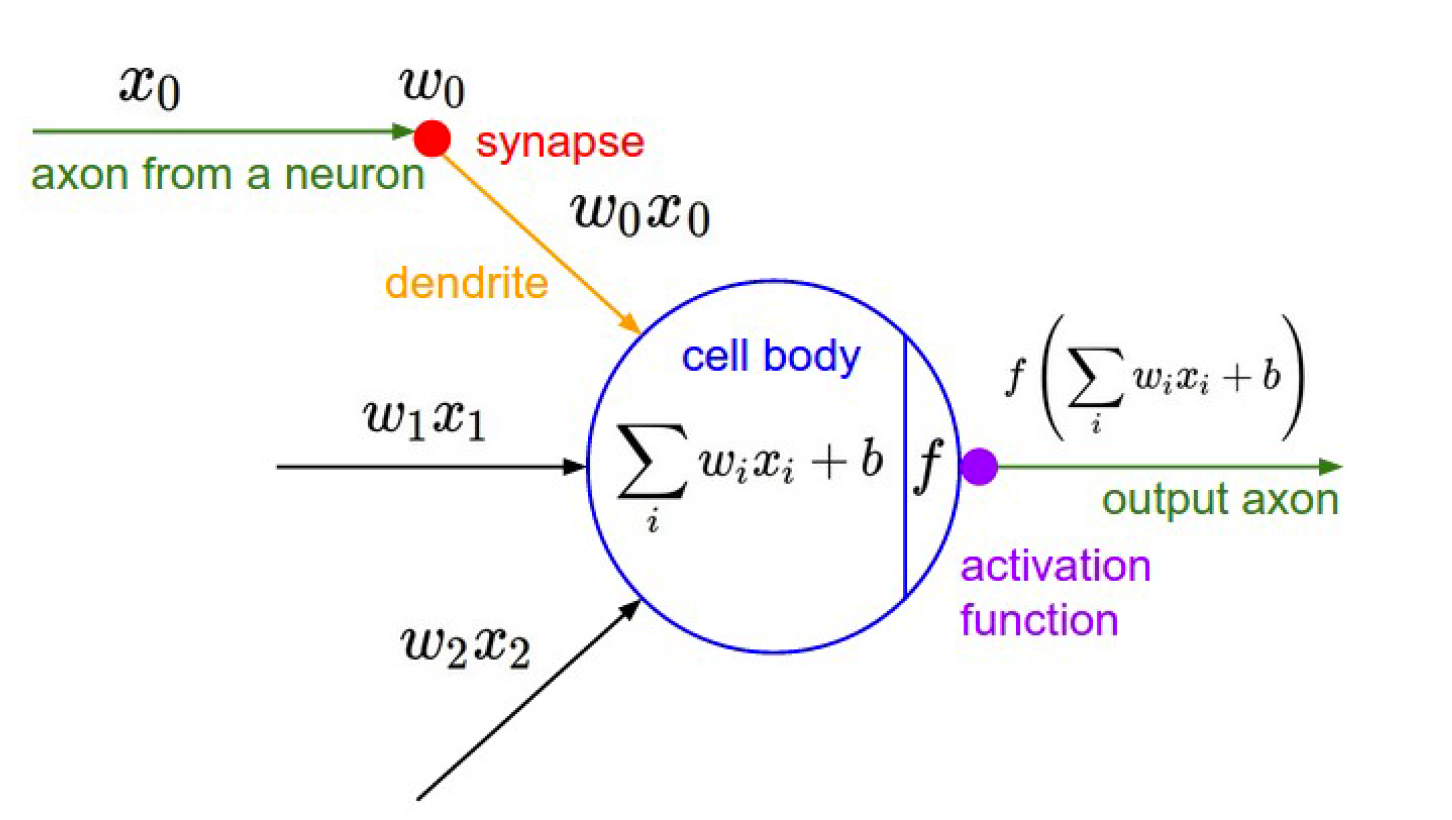
A neuron can be a binary logistic regression unit
我们令
则一个 logistic regression 单元可以表示为
$b$ : 我们可以有一个“总是打开”的特性,它给出一个先验类,或者将它作为一个偏向项分离出来
$w,b$ 是神经元的参数
A neural network = running several logistic regressions at the same time
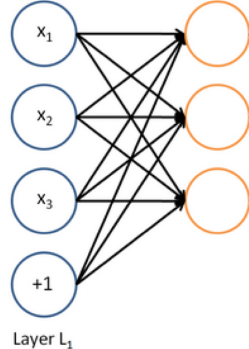
如果我们输入一个向量通过一系列逻辑回归函数,那么我们得到一个输出向量,但是我们不需要提前决定这些逻辑回归试图预测的变量是什么。
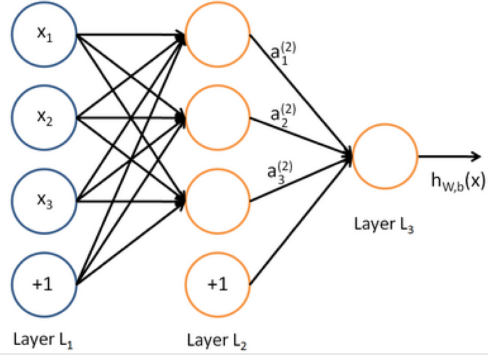
我们可以输入另一个logistic回归函数。损失函数将指导中间隐藏变量应该是什么,以便更好地预测下一层的目标。我们当然可以使用更多层的神经网络。
Matrix notation for a layer
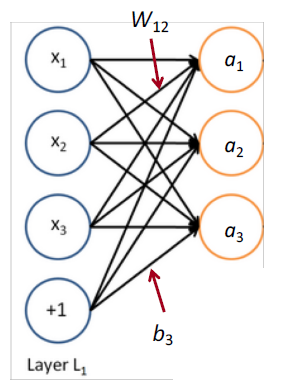
$f(x)$ 在运算时是 element-wise 逐元素的
Non-linearities (aka “f ”): Why they’re needed
例如:函数近似,如回归或分类
- 没有非线性,深度神经网络只能做线性变换
*多个线性变换可以组成一个的线性变换 $W_1 W_2 x = Wx$- 因为线性变换是以某种方式旋转和拉伸空间,多次的旋转和拉伸可以融合为一次线性变换
- 对于非线性函数而言,使用更多的层,他们可以近似更复杂的函数
3 Named Entity Recognition (NER)
- 任务:例如,查找和分类文本中的名称

- 可能的用途
- 跟踪文档中提到的特定实体(组织、个人、地点、歌曲名、电影名等)
- 对于问题回答,答案通常是命名实体
- 许多需要的信息实际上是命名实体之间的关联
- 同样的技术可以扩展到其他 slot-filling 槽填充 分类
- 通常后面是命名实体链接/规范化到知识库
Named Entity Recognition on word sequences

我们通过在上下文中对单词进行分类,然后将实体提取为单词子序列来预测实体
Why might NER be hard?
- 很难计算出实体的边界

- 第一个实体是 “First National Bank” 还是 “National Bank”
- 很难知道某物是否是一个实体
- 是一所名为“Future School” 的学校,还是这是一所未来的学校?
- 很难知道未知/新奇实体的类别

- “Zig Ziglar” ? 一个人
- 实体类是模糊的,依赖于上下文

- 这里的“Charles Schwab” 是 PER 不是 ORG
4 Binary word window classification
为在上下文中的语言构建分类器
- 一般来说,很少对单个单词进行分类
- 有趣的问题,如上下文歧义出现
- 例子:auto-antonyms
- “To sanction” can mean “to permit” or “to punish”
- “To seed” can mean “to place seeds” or “to remove seeds”
- 例子:解决模糊命名实体的链接
- Paris → Paris, France vs. Paris Hilton vs. Paris, Texas
- Hathaway → Berkshire Hathaway vs. Anne Hathaway
Window classification
- 思想:在相邻词的上下文窗口中对一个词进行分类
- 例如,上下文中一个单词的命名实体分类
- 人、地点、组织、没有
- 在上下文中对单词进行分类的一个简单方法可能是对窗口中的单词向量进行平均,并对平均向量进行分类
- 问题:这会丢失位置信息
Window classification: Softmax
- 训练softmax分类器对中心词进行分类,方法是在一个窗口内将中心词周围的词向量串联起来
- 例子:在这句话的上下文中对“Paris”进行分类,窗口长度为2
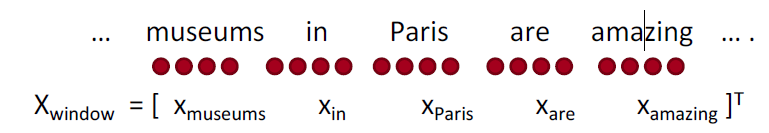
结果向量 $x_{window} = x \in R^{5d}$ 是一个列向量
Simplest window classifier: Softmax
对于 $x = x_{window}$ ,我们可以使用与之前相同的softmax分类器

- 如何更新向量?
- 简而言之:就像上周那样,求导和优化
Binary classification with unnormalized scores
- 之前的例子:$X_{\text { window }}=[\begin{array}{ccc}{\mathrm{X}_{\text { museums }}} & {\mathrm{X}_{\text { in }}} & {\mathrm{X}_{\text { paris }} \quad \mathrm{X}_{\text { are }} \quad \mathrm{X}_{\text { amazing }} ]}\end{array}$
- 假设我们要对中心词是否为一个地点,进行分类
- 与word2vec类似,我们将遍历语料库中的所有位置。但这一次,它将受到监督,只有一些位置能够得到高分。
- 例如,在他们的中心有一个实际的NER Location的位置是“真实的”位置会获得高分
Binary classification for NER Location
例子:Not all museums in Paris are amazing
一个正确的窗口需要以以Paris为中心,下面这个就是正确的窗口,我们可以看到Paris位于这个窗口的正中央。而中心词没有指定实体Location的窗口,我们称之为是broken的。
- museums in Paris are amazing
- “损坏”窗口很容易找到,而且有很多:任何中心词没有在我们的语料库中明确标记为NER位置的窗口,比如说
- Not all museums in Paris
Neural Network Feed-forward Computation
使用神经元激活函数 $a$ 简单地给出一个非标准化的分数
我们用一个三层神经网络(实际上只有单隐层)计算一个窗口的得分
- $s = score(“museums \ in \ Paris \ are \ amazing”)$

Main intuition for extra layer
中间层学习输入词向量之间的非线性交互
例如:只有当“museum”是第一个向量时,“in”放在第二个位置才重要
The max-margin loss
- 关于训练目标的想法:让真实窗口的得分更高,而破坏窗口的得分更低(直到足够好为止)
- $s = score(“museums \ in \ Paris \ are \ amazing”)$
- $s_c = score(“Not \ all \ museums \ in \ Paris)$
- 最小化 $J=\max \left(0,1-s+s_{c}\right)$
- 这是不可微的,但它是连续的→我们可以用SGD。
- 每个选项都是连续的
- 单窗口的目标函数为
- 每个中心有NER位置的窗口的得分应该比中心没有位置的窗口高1分
1560361673756 - 要获得完整的目标函数:为每个真窗口采样几个损坏的窗口。对所有培训窗口求和
- 类似于word2vec中的负抽样
- 使用SGD更新参数
- $\theta^{n e w}=\theta^{o l d} - \alpha \nabla_{\theta} J(\theta)$
- $a$ 是 步长或是学习率
- 如何计算 $\nabla_{\theta} J(\theta)$ ?
- 手工计算(本课)
- 算法:反向传播(下一课)
Computing Gradients by Hand
- 回顾多元导数
- 矩阵微积分:完全矢量化的梯度
- 比非矢量梯度快得多,也更有用
- 但做一个非矢量梯度可以是一个很好的实践;以上周的讲座为例
- notes 更详细地涵盖了这些材料
5 Gradients
给定一个函数,有1个输出和1个输入
斜率是它的导数
给定一个函数,有1个输出和 $n$ 个输入
梯度是关于每个输入的偏导数的向量
Jacobian Matrix: Generalization of the Gradient
给定一个函数,有 $m$ 个输出和 $n$ 个输入
其雅可比矩阵是一个$m \times n$的偏导矩阵
Chain Rule
对于单变量函数:乘以导数
对于一次处理多个变量:乘以雅可比矩阵
Example Jacobian: Elementwise activation Function
由于使用的是 element-wise,所以 $h_{i}=f\left(z_{i}\right)$
函数有$n$个输出和$n$个输入 → $n \times n$ 的雅可比矩阵
Other Jacobians
这是正确的雅可比矩阵。稍后我们将讨论“形状约定”;用它则答案是 $h$ 。
Back to our Neural Net!
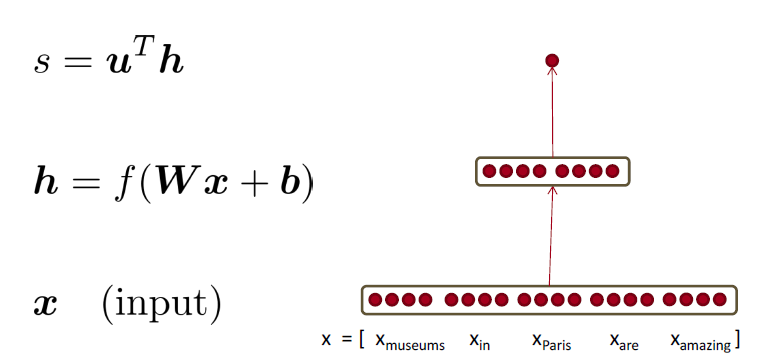
如何计算 $\frac{\partial s}{\partial b}$ ?
实际上,我们关心的是损失的梯度,但是为了简单起见,我们将计算分数的梯度
Break up equations into simple pieces
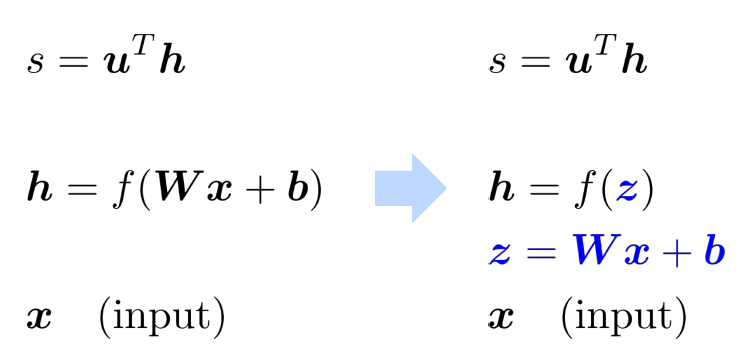
Apply the chain rule
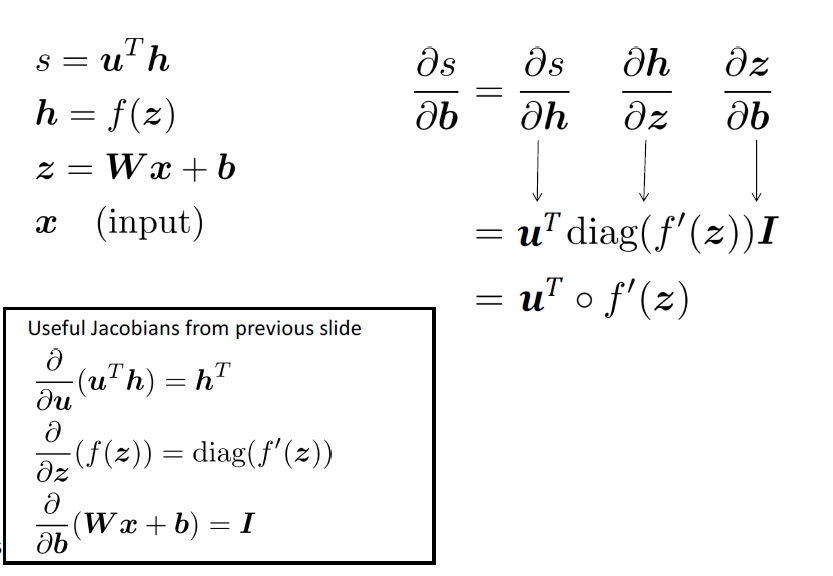
如何计算 $\frac{\partial s}{\partial \textbf{W}}$ ?
前两项是重复的,无须重复计算
其中,$\delta$ 是局部误差符号
Derivative with respect to Matrix: Output shape
- $\boldsymbol{W} \in \mathbb{R}^{n \times m} ,\frac{\partial s}{\partial \boldsymbol{W}}$ 的形状是
- 1个输出,$n \times m $个输入:$1 \times nm$ 的雅可比矩阵?
- 不方便更新参数 $\theta^{n e w}=\theta^{o l d}-\alpha \nabla_{\theta} J(\theta)$
- 而是遵循惯例:导数的形状是参数的形状 (形状约定)
- $\frac{\partial s}{\partial \boldsymbol{W}}$ 的形状是 $n \times m$
Derivative with respect to Matrix
- $\frac{\partial s}{\partial \boldsymbol{W}}=\boldsymbol{\delta} \frac{\partial \boldsymbol{z}}{\partial \boldsymbol{W}}$
- $\delta$ 将出现在我们的答案中
- 另一项应该是 $x$ ,因为 $\boldsymbol{z}=\boldsymbol{W} \boldsymbol{x}+\boldsymbol{b}$
- 这表明 $\frac{\partial s}{\partial \boldsymbol{W}}=\boldsymbol{\delta}^{T} \boldsymbol{x}^{T}$

Why the Transposes?
- 粗糙的回答是:这样就可以解决尺寸问题了
- 检查工作的有用技巧
- 课堂讲稿中有完整的解释
- 每个输入到每个输出——你得到的是外部积
What shape should derivatives be?
- $\frac{\partial s}{\partial \boldsymbol{b}}=\boldsymbol{h}^{T} \circ f^{\prime}(\boldsymbol{z})$ 是行向量
- 但是习惯上说梯度应该是一个列向量因为 $b$ 是一个列向量
- 雅可比矩阵形式(这使得链式法则很容易)和形状约定(这使得SGD很容易实现)之间的分歧
- 我们希望答案遵循形状约定
- 但是雅可比矩阵形式对于计算答案很有用
- 两个选择
- 尽量使用雅可比矩阵形式,最后按照约定进行整形
- 我们刚刚做的。但最后转置 $\frac{\partial s}{\partial \boldsymbol{b}}$ 使导数成为列向量,得到 $\delta ^ T$
- 始终遵循惯例
- 查看维度,找出何时转置 和/或 重新排序项。
- 尽量使用雅可比矩阵形式,最后按照约定进行整形
反向传播
- 算法高效地计算梯度
- 将我们刚刚手工完成的转换成算法
- 用于深度学习软件框架(TensorFlow, PyTorch, Chainer, etc.)