
The Tencent AI Lab’s paper - Hierarchical Macro Strategy Model
OpenAI Five’s paper - Micro level execution Model
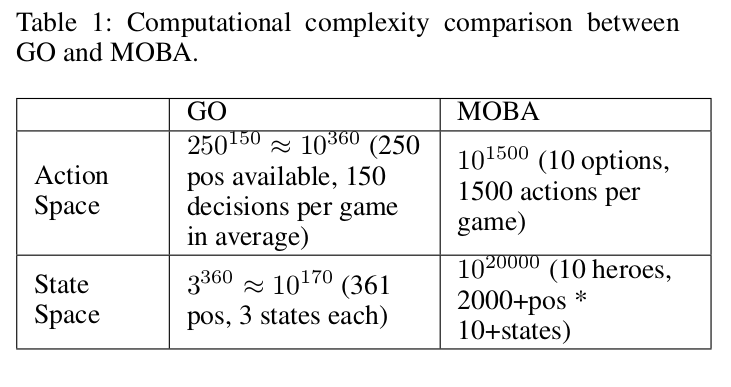
Recently I have read a paper writen by Tencent AI Lab talking about playing one of my favourite MOBILE GAME Arena of Valor (also called Honour of Kings or Strike of Kings) by AI with macro strategy. I spontaneously remember AlphaGo developed by DeepMind had defeated the world GO champion Lee Seedol which deeply impressed my at that time. Then, Since AI has occupied the last human’s intelligent force - GO, where do AI go next and what the following obstacle that AI need to conquer? To our best knowledge, it is RTS (Real Time Strategy) Game which goes a step further to our real world situation such as cooperation, strategy and actions. And responsible for more than 30% of the online gameplay all over the world, Multiplayer Online Battle Arena (MOBA) games are representatives of RTS Game. In the Table 1, we can see the difference between GO and MOBA and know why Mastering RTS is the next AI developed direction.
In August 2018, OpenAI Five, an AI DOTA team, played against humans team in the International DOTA2 Championships. Though it showed a strong team-fighting skills and professional micro level execution, it finally lost the game. To analyse the contest statistics, OpenAI was really powerful at the opening, killing more people and having more gold. However, as the game went on, the gap between the two teams had been gradually narrowed and to the mid-to-late period human players had already crushed its opponents, especially over 10 thousands than OpenAI Five. In the end, the AI only gave its rate of winning in poor 1%. The DeepMind said in their blog that their OpenAI lacked the explicit macro strategy definition and just tried to learn the entire game using micro level play.
To let AI master the ability of macro strategy, the Tencent AI Lab has proposed a Hierarchical Macro Strategy Model which makes its 5-AI team achieves a 48% winning rate against human player teams which are ranked top 1% in the player ranking system.
I has played with terrible 5-AI team and I can’t believe these are AIs because they are even better than most of my friends who plays the game at Diamond and Platinum ranking. After a big technology upgrade to 2.0 version, the AI mode is upgraded to Super AI Mode which the AIs do really know how to cooperate and use macro strategy against opponents.
1 Define the Macro Strategy
To let the 5-AI know the macro strategy, first we need to define what macro strategy is. Therefore, a explicit model definition is strongly needed. What we call Macro Strategy can be simplified to one description - Arrive to the RIGHT place at RIGHT time. For example, during the laning phase players tend to focus more on their own lanes rather than backing up allies, while during mid to late phases, players pay more attention to teamfight spots and pushing enemies’ base. Also the players need to understand that Jungle needs to gank the enemies when upgrading to 4 level, Support need to protect the Archer and when inner jungle area is invaded agents need to assemble to fight.
So there are two elements in our designed model - Time and Place. In tencent’s paper, they define parse layer (Time) and attention layer(Place) to describe the macro strategy operation. Parse layer needs to recognize the stage of a game (opening, laning, mid and late period) and the attention layer will decide where to dispatch an agent, just like the function of navigation drawing a line to move from one place to another. To sum up, the macro strategy operation process can be describe as ‘phase recognition -> attention prediction -> execution’.
1.1 Parse Layer
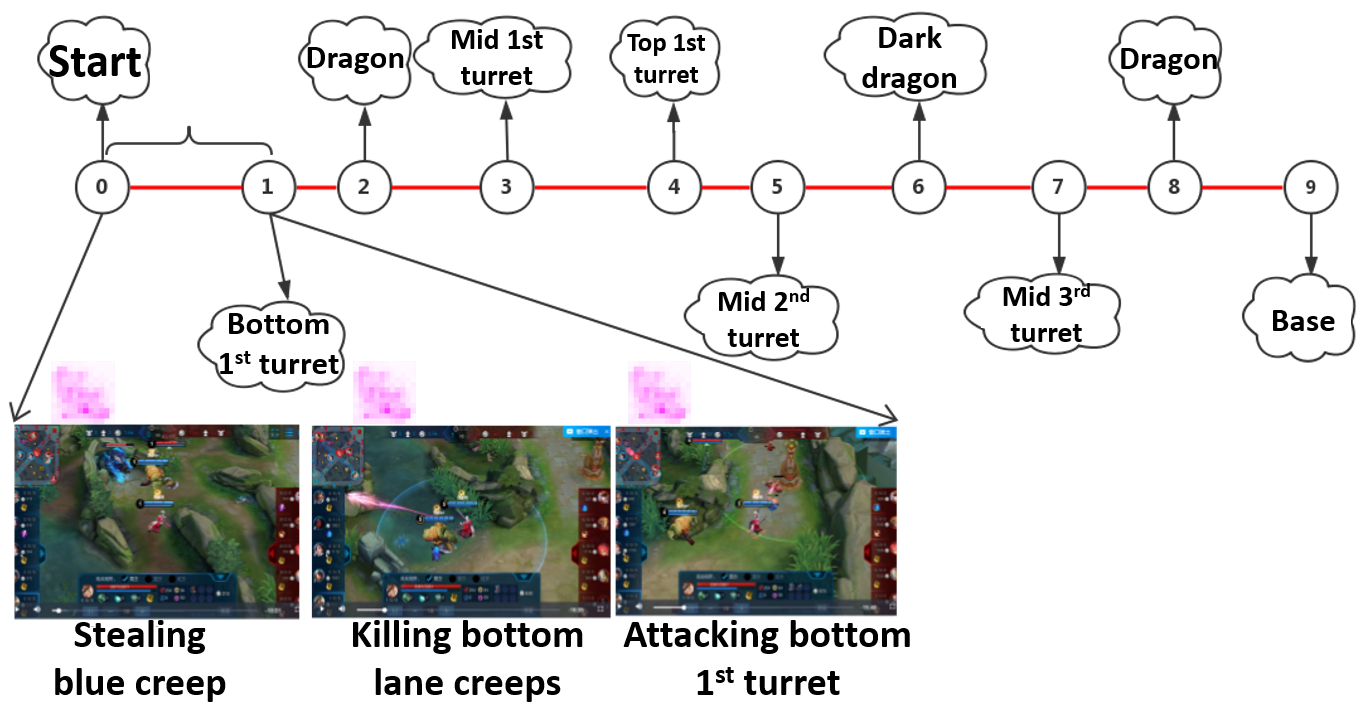
The next picture shows an example of an parse division in one game. The Tencent AI team extracts the label tagging different resources and place them in the from of timeline. In different phase, the 5-AI have different goal to achieve. The picture for example, during from stage 0 to 1, the 5-AI stealing blue creep, killing bottom lane creeps and the other actions they take finally aim to destroy the 1st turret.
1.2 Attention Layer
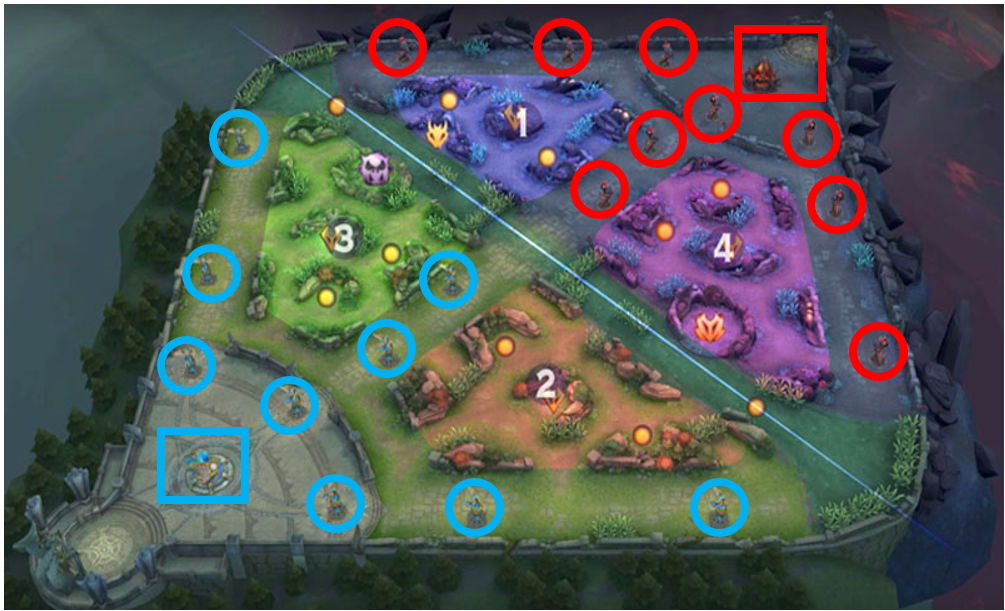
One the one hand, it’s easy to understand different agents play different roles in one game. 80+ heroes have different attributes so that they should pay attention to different area. On the other hand, as the game develops, the agent’s attention distribution also need to change. For example, this picture shows in the opening period, different heroes - Diaochan, Hanxin, Arthur, and Houyi which belong to master, assasin, warrior, and archer respectively, are dispatched to different areas. The more darker blue means the more possible place they would reach and pay more attention to.

Diaochan is dispatched to middle lane, Hanxin will move to left jungle area, and Authur and Houyi will guard the bottom jungle area. The fifth hero Miyamoto Musashi, which was not plotted, will guard the top outer turret. And this opening is considered safe and efficient, and widely used in Honour of Kings games.
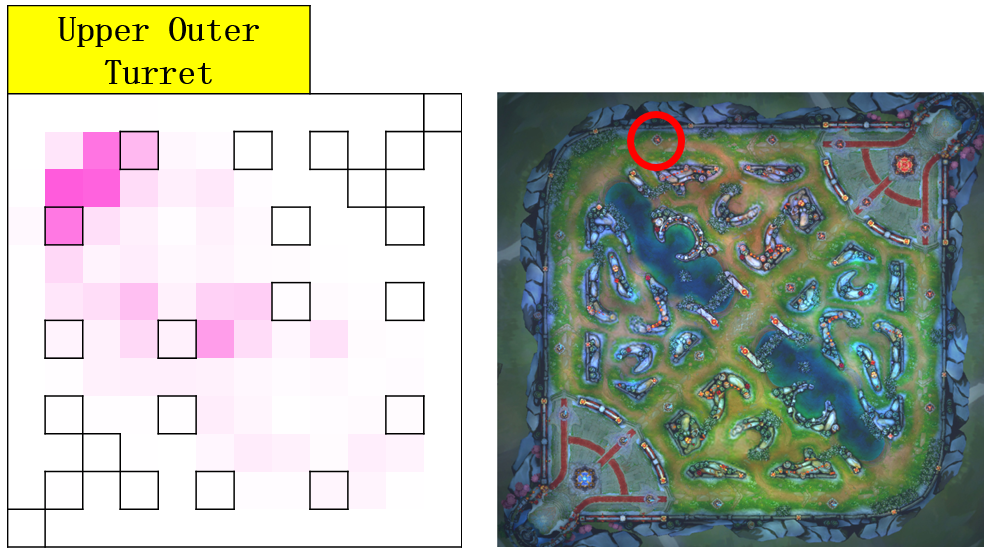
The next two pictures shows different phases have different strategies which can be described as Attention Distribution Map. When in upper outer turret period, AI needs to occupy the 1st turret as soon as possible and they need to destroy the enemy’s base in base period.
1.3 Imitated Cross-agents Communication
More importantly, Tencent AI Lab Team has developed a novel way to teach AI to communicate and they name this method or mechanism as Imitated Cross-agents Communication. During training phase, they put attention labels of allies as features for training. During testing phase,they put attention prediction of allies as features and make decision correspondingly. In this way, our agents can communicate with one another and learn to cooperate upon allies’ decisions.
2 Hierarchical Macro Strategy Model (HMS)
We can see the structure of HMS model in the following picture.
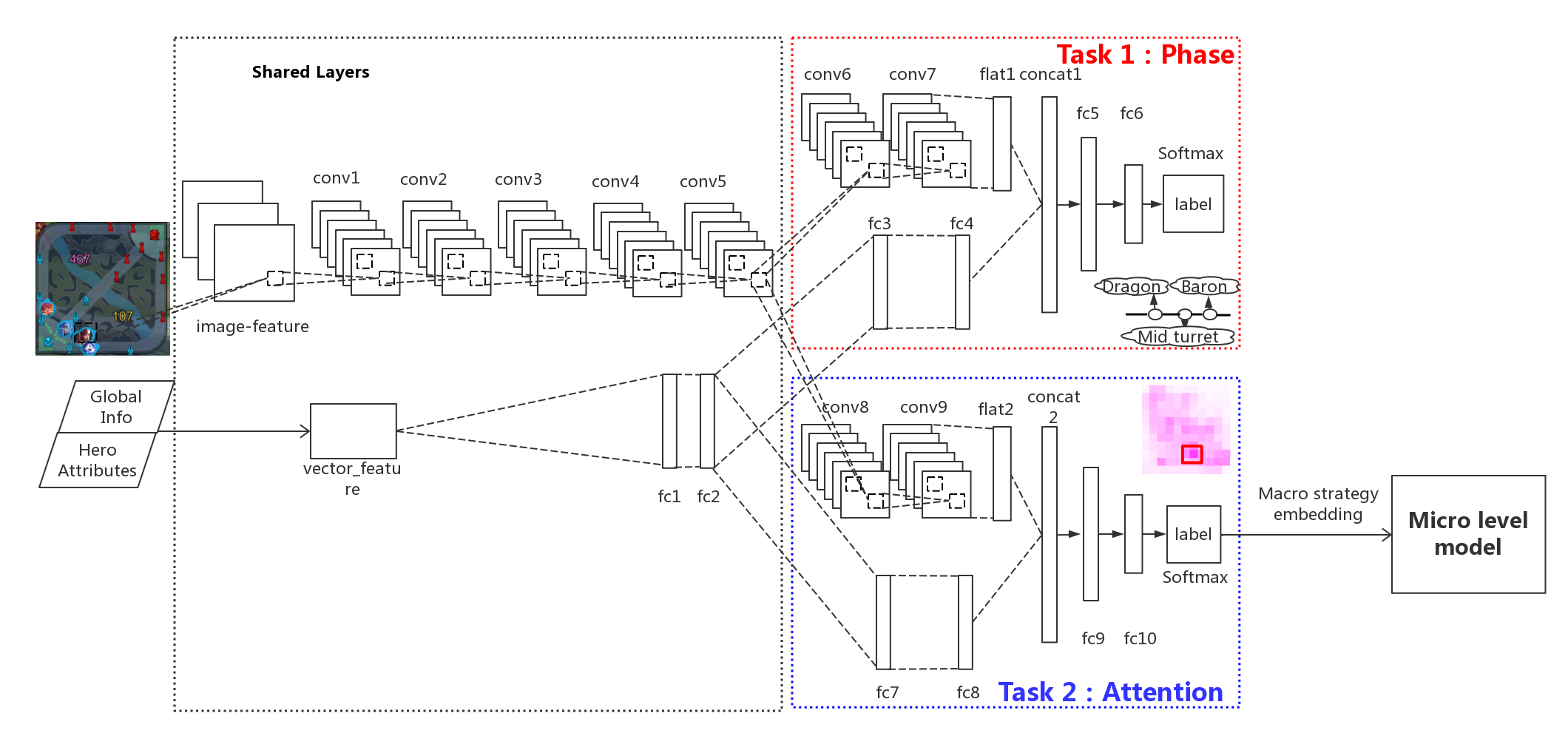
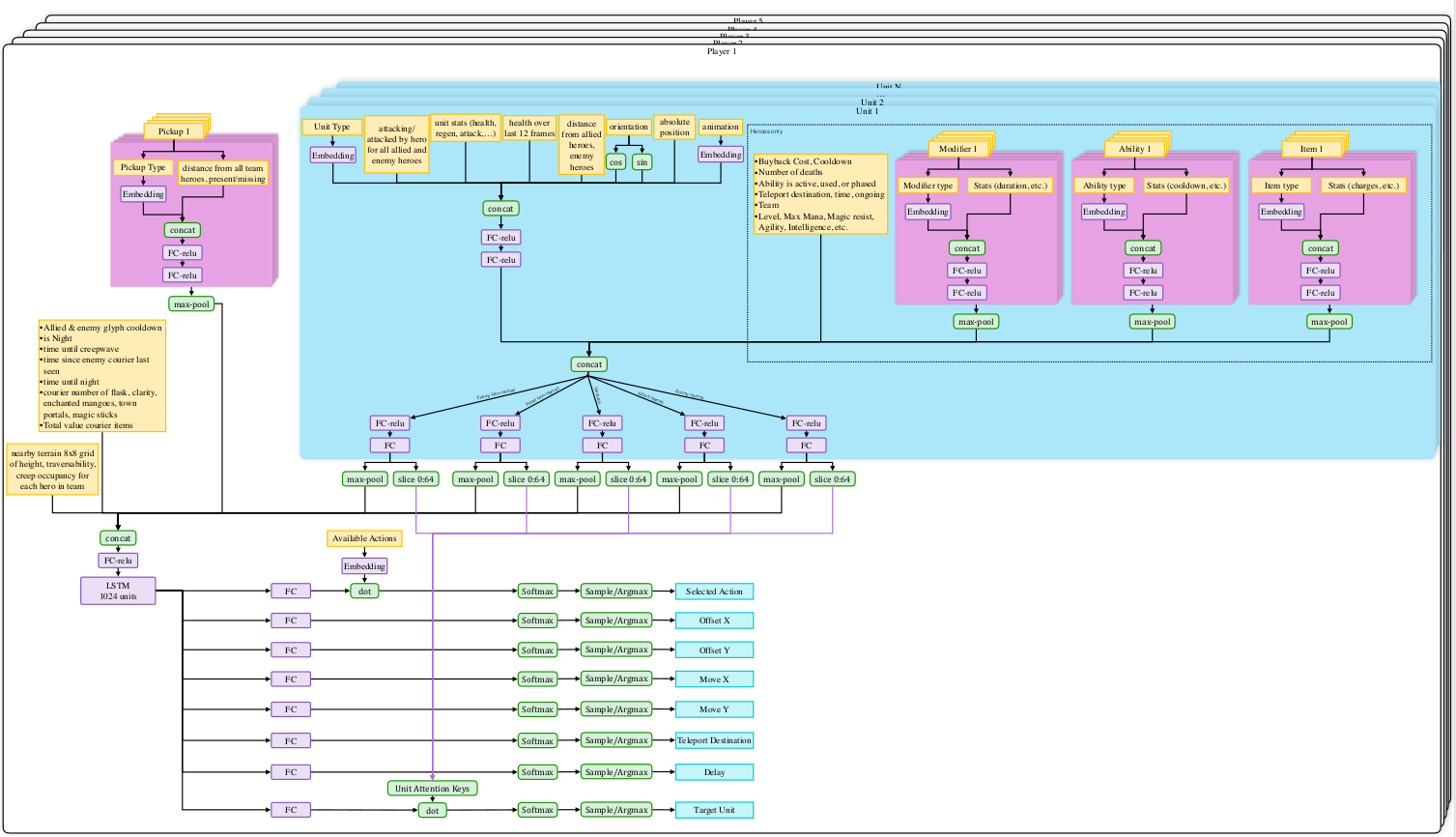
Phase and Attention layers act as high level guidance for micro level execution. The network structure of micro level model is almost identical to the one used in OpenAI Five 1(OpenAI 2018a), but in a supervised learning manner. They did minor modification to adapt it to Honour of Kings, such as deleting Teleport.
The detailed architecture of the OpenAI Five Model is showed in this Pic.
2.1 Data Preparation
To train a model, they collect around 300 thousand game replays made of King Professional League competition (KPL) and training records. Finally, 250 million instances were used for training. They consider both visual and attributes features. On visual side, they extract 85 features such as position and hit points of all units and then blur the visual features into 12*12 resolution. On attributes side, they extract 181 features such as roles of heroes, time period of game, hero ID, heroes’ gold and level status and Kill-Death-Assistance statistics.
2.2 Model Setup
They use a mixture of convolutional and fully-connected layers to take inputs from visual and attributes features respectively. On convolutional side, they set five shared convolutional layers, each with 512 channels, padding = 1, and one RELU. Each of the tasks has two convolutional layers with exactly the same configuration withshared layers. On fully-connected layers side, they set two shared fully-connected layers with 512 nodes. Each of the tasks has two fully-connected layers with exactly the same configuration with shared layers. Then, they use one concatenation layer and two fully-connected layers to fuse results of convolutional layers and fully-connected layers. They use ADAM as the optimizer with base learning rate at 10e-6. Batch size was set at 128. The loss weights of both phase and attention tasks are set at 1. We used CAFFE (Jia et al.2014) with eight GPU cards. The duration to train an HMS model was about 12 hours.
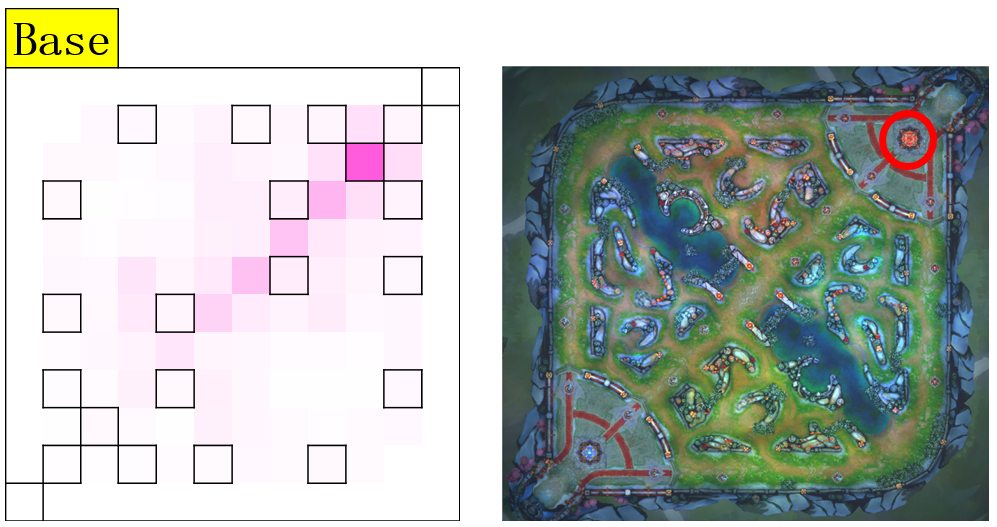
Finally, the output for attention layer corresponds to 144 regions of the map, resolution of which is exactly the same as the visual inputs. The output of the phase task corresponds to 14 major resources circled in the following picture.

3 Result of using HMS Model to battle
The research team invited 250 human player teams whose average ranking is King in Honour of Kings rank system (above 1% of human players). Following the standard procedure of ranked match in Honour of Kings, they obey ban-pick rules to pick and ban heroes before each match.
3.1 Against with different opponents
In the table, the bold parts are the 5-AI’s statistics. Its opponents are AI Without Macro Strategy, Human Teams, AI Without Communication, AI Without Phase Layer.
- AI Without Macro Strategy - AI is trained only using OpenAI Five Micro Level Model
- Human Teams - Human whose average ranking is King in Honour of Kings rank system
- AI Without Communication - AI is trained by both OpenAI Five Micro Level Model and HMS, but not using Imitated Cross-agents Communication
- AI Without Phase Layer - AI is trained by both OpenAI Five Micro Level Model and HMS without phase layer
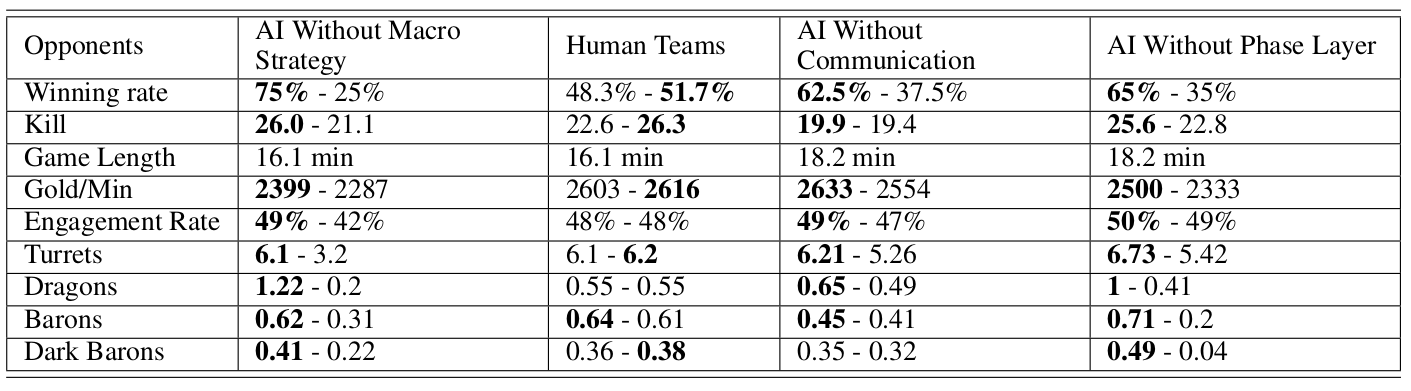
We can see that the HMS-5-AI is much stronger than AI Without Macro Strategy, AI Without Communication, AI Without Phase Layer and are close to the human’s abilities.
3.2 Attention Distribution Affected by Phase Layer
They conduct t-Distributed Stochastic Neighbor Embedding (t-SNE) on phase layer output. As shown in this picture, samples are coloured with respect to different time stages. We can observe that samples are clearly separable with respect to time stages. For example, blue, orange and green (0-10 minutes) samples place close to one another, while red and purple samples (more than 10 minutes) form another group.
