参考自英文原文Deobfuscation: recovering an OLLVM-protected program和FreeBuff的中译文《反混淆:恢复被OLLVM保护的程序》
混淆是什么
代码混淆意味着代码保护。混淆修改后的代码更难以被理解。例如它通常被用于DRM(数字版权保护)软件中,通过隐藏算法和加密密钥等机密信息来保护多媒体内容。
当任何人都可以获取访问你的代码或二进制程序,但你不想让别人了解程序的工作原理的时候,你就需要代码混淆。但混淆的安全性基于代码模糊程度,破解它也只是时间问题。因此混淆工具的安全性取决于攻击者打破它所必须花费的时间。
O-LLVM
O-LLVM全称为Obfuscator-LLVM,它是基于LLVM架构设计的代码混淆器,也是Github上的开源项目,里面的Obfuscator就是混淆器的意思,通过横向对比分析,其大部分的源码是与LLVM对齐的,那不同的地方在哪里呢?
从前面的两篇文章中《LLVM简述》和《LLVM的三段式架构》中我们可以看出LLVM尝试并真正实现编译器的三段式架构,提供了良好的中间表达式(Intermediate Representation)的支持,便于不同语言间的相互转换。既然LLVM能够作为一个优秀的编译器架构,比如将C转换为Machine Code,那我们为何利用这个框架,把它打造成一个混淆器呢?O-LLVM的思路便是:我们只需要将中间表达式混淆,那么生成的Machine Code也是混淆的,并且由于中间表达式的“中立”特性,还可以生成适用于不同平台的混淆程序。LLVM里面有一个pass的概念,LLVM会依照pass定义的规则来编译代码,所以O-LLVM通过编写pass命令,实现了中间表达式的混淆转换。
O-LLVM提供三种保护方式:控制流平坦化,虚假控制流和指令替换,这些保护方式可以累加,而对于静态分析来说混淆后代码非常复杂。下面我们会先介绍着三种代码混淆的技术,然后看看O-LLVM是怎样实现的
三种代码混淆技术
控制流平坦化(Control Flow Flattening)
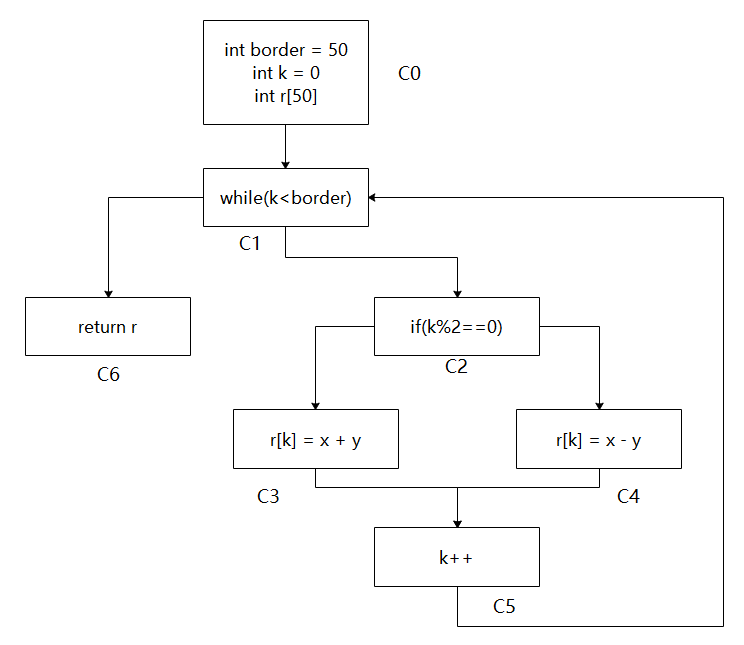
程序的结构可以分为顺序、判断和循环三个基本结构,而控制流平坦化就是将原始程序的控制结构——条件判断和循环全部平坦化成一个循环分发器的结构。具体的做法就是把代码分为若干的基本块,将块全部放在一个switch语句块中,然后再把这个switch语句块封锁到一个死循环里面,将原先的代码结构隐藏起来。下面将举一个例子说明如何进行代码的控制流平坦化,下面的代码在函数体calculate()中包含一个循环结构和分支结构:
1 | int calculate(int x, int y) { |
我们可以它的控制流图:
!!!
!!!
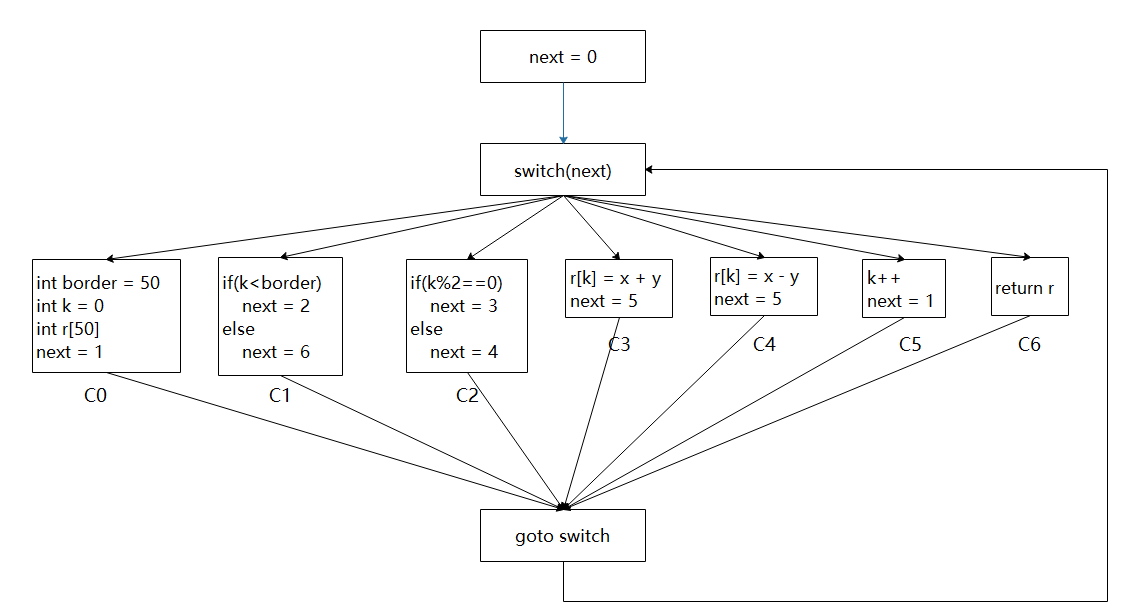
原先的代码被分为7个基本块,依次给代码块编号为C0~C6,接着使用switch-case的结构根据编号的顺序,将程序的基本块放置在对应的分支中,用next变量用于指明下一个要执行的基本块的编号,最后将整个switch-case结构封锁在死循环中。同样,作出平坦化代码的控制流图,可以观察到原先代码的循环和分支结构被破坏了,被“展平”成下图中的结构。对于运行这段代码的系统来说,每个基本块后的next变量都指明了下一个基本块,运行过程与平坦化前的代码没有区别;但是对于恶意的逆向者而言,需要恢复控制流图,才能理解程序的意义,这无疑增大了逆向的难度。
1 | int next = 0; |
!!!
!!!
虚假控制流(Bogus Control Flow)
(1)垃圾代码(Junk Code)
垃圾代码是指插入到原始程序代码中,会被执行但是不会改变程序运行结果的代码。垃圾代码分为不相关代码和死代码,不相关代码指的是与源代码无关的代码;而后者是程序运行永远不会被执行到的代码。可以利用堆栈、循环、分支结构来构造垃圾代码。
(2)不透明谓词(Opaque Predicate)
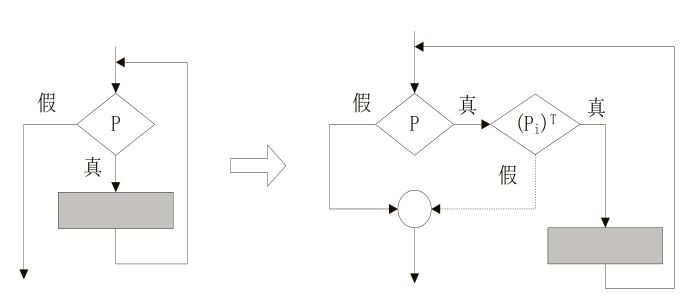
不透明谓词是一种最常见的不透明表达式,它的定义如下:设$i \in \{1, 2, \cdots, n\}$,存在Pi,当程序中点$p$上的输出在混淆程序之前就已确定时,称谓词$P_i$在点$p$上是不透明谓词。如果$P_i$的输出一直为真,就记作$(P_i)^T$;如果$P_i$的输出一直为假,就记作$(P_i)^F$;如果Pi的输出时为真时为假,就记作$(Pi)^?$。如图3所示,这是不透明谓词的三种常见的形式。
不透明谓词具有难以推断的特点,但是总可以根据运行的值与计算判断真正的执行路径,它可以增加破解的成本,但是不能真正阻挡逆向的步伐。比如图4中的不透明谓词是一个数学表达式,需要判断$(x^2 + x)^T$是否能整除2才能判断程序真正的执行路径,而$x$与$T$的值随着程序的执行而发生变化,表达式的值既可能在真与假中摇摆,也可能始终为真或者假,这就导致分支的不确定性。

!!!
!!!
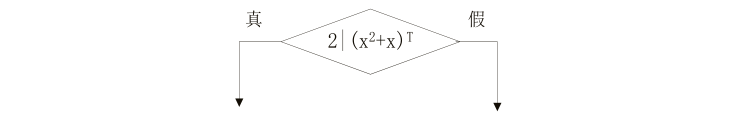
!!!
!!!
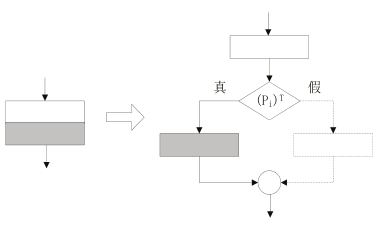
借助不透明谓词与垃圾代码可以构造虚假的控制流,最常见的块分裂和不确定循环。块分裂常用于顺序结构中,如图5所示,构造了一个永为真的不透明谓词,右边的分支永远不会执行,里边被填充了垃圾代码,用于迷惑逆向者;而不确定循环则是在循环前插入一个不透明谓词,逆向者需要判断不透明谓词的真假才能确定是否进入循环体。如图6在循环中插入了一个永真的不透明谓词,循环一定会执行。
!!!
!!!
!!!
!!!
指令替代(Instructions Substitution)
这种混淆技术的目标仅仅在于用功能等同但更复杂的指令序列替换标准二元运算符(如加法,减法或布尔运算符)。当有几个等效指令序列可用时,随机选择一个。
这种混淆是相当简单的,并没有增加很多安全性,因为它可以通过重新优化生成的代码轻松删除。但是,如果伪随机生成器以不同的值播种,则指令替换会在生成的二进制文件中带来多样性。
加法
a = b - (-c)
1 | %0 = load i32* %a, align 4 |
r = rand (); a = b + r; a = a + c; a = a – r1
2
3
4
5%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = add i32 %0, 1107414009
%3 = add i32 %2, %1
%4 = sub nsw i32 %3, 1107414009
r = rand (); a = b - r; a = a + b; a = a + r1
2
3
4
5%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = sub i32 %0, 1108523271
%3 = add i32 %2, %1
%4 = add nsw i32 %3, 1108523271
减法
a = b + (-c)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = sub i32 0, %1
%3 = add nsw i32 %0, %2
r = rand (); a = b + r; a = a - c; a = a - r
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = add i32 %0, 1571022666
%3 = sub i32 %2, %1
%4 = sub nsw i32 %3, 1571022666
r = rand (); a = b - r; a = a - c; a = a + r
%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = sub i32 %0, 1057193181
%3 = sub i32 %2, %1
%4 = add nsw i32 %3, 1057193181
与运算AND
a = b & c => a = (b ^ ~c) & b1
2
3
4
5%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = xor i32 %1, -1
%3 = xor i32 %0, %2
%4 = and i32 %3, %0
或运算OR
a = b | c => a = (b & c) | (b ^ c)1
2
3
4
5%0 = load i32* %a, align 4
%1 = load i32* %b, align 4
%2 = and i32 %0, %1
%3 = xor i32 %0, %1
%4 = or i32 %2, %3
异或运算XOR
a = a ^ b => a = (~a & b) | (a & ~b)
1 | %0 = load i32* %a, align 4 |
使用O-LLVM混淆代码
测试例子
我们的测试目标是一个对输入值进行简单计算的单一函数。代码包含4个条件分支,这些分支取决于输入参数。测试程序在x86 32位架构下编译:
1 | unsigned int target_function(unsigned int n) |
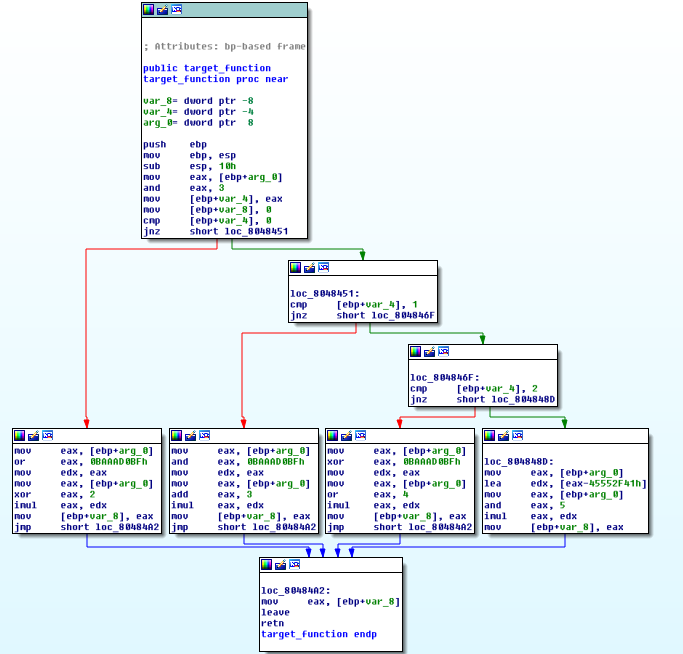
下面是IDA的控制流程图展示:
!!!
!!!
我们可以看到使用布尔比较和算术指令计算的3个条件和4个分支路径。我们这样做的目的是为了充分测试O-LLVM所有的混淆策略。
控制流平坦化
使用以下命令行编译测试代码:
1 | ../build/bin/clang -m32 target.c -o target_flat -mllvm -fla -mllvm -perFLA=100 |
这个编译命令会对我们的测试程序所有函数开启“控制流平坦化”保护,以便确保我们的测试具有针对性。
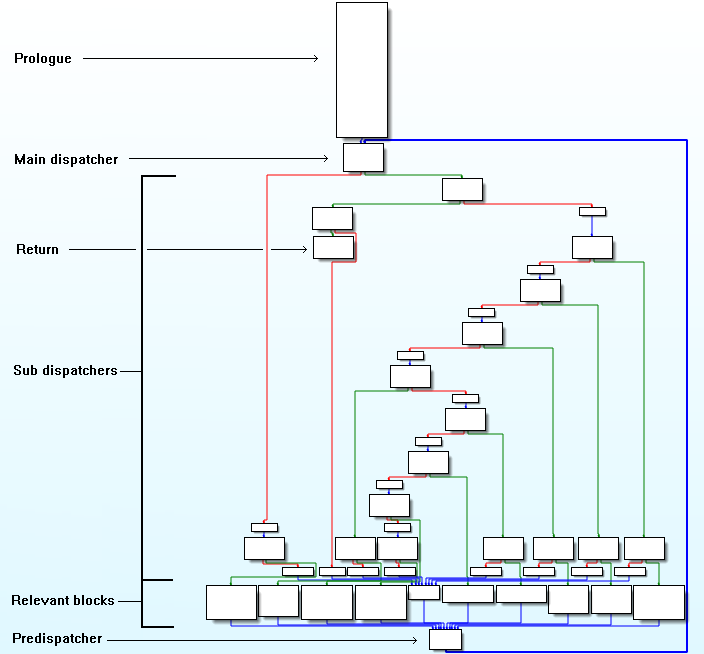
通过IDA查看被混淆目标函数的控制流图如下:
!!!
!!!
虚假控制流
使用以下命令行编译测试代码:
1 | ../build/bin/clang-m32 target.c -o target_flat -mllvm -bcf -mllvm -boguscf-prob=100 -mllvm-boguscf-loop=1 |
该编译命令可以在我们的测试程序的函数上启用“虚假控制流”保护。我们将-boguscf-loop参数(循环次数)设置为1,只是代码生成和恢复过程会比较慢,并且内存消耗更多。
当我们使用IDA Pro加载目标程序时,控制流图如下:

!!!
!!!
屏幕分辨率在这里已变得不再重要,因为从上图中我们足以看出混淆后的函数代码非常复杂。“虚假控制流”保护会对每个基本块进行混淆,创建一个包含“不透明谓词”的新代码块,“不透明谓词”会生成条件跳转:可以跳转到真正的基本块或另一个包含垃圾指令的代码块。
指令替代
使用以下命令行编译测试代码:
1 | ../build/bin/clang -m32 target.c -o target_flat -mllvm -subv |
上述编译命令会在我们的测试程序的所有函数开启“指令替换”保护。
“指令替换”保护不会修改函数原始的控制流程,图形展示中如下:

!!!
!!!
正如期望的那样,函数流程图“形状”没有改变,仍可以看到相同的条件分支,但是在“相关块”中,可以看到对输入值的计算过程变得更繁杂。因为这个例子中代码比较简单,所以混淆复杂度看起来还能够接受,但如果是比较庞大的函数源码,这样的混淆也足够恶心。 OLLVM项目把普通算术和布尔运算替换为更复杂的操作。
完整保护
逐个打破所有的保护是个可行的思路,通常来说,混淆器的保护力度是可以被叠加的,这使得未处理的混淆代码很难被理解。另外在现实情况中,一般都会启用最大保护级别去混淆模糊目标软件代码。所以能够处理完整保护显得非常重要。
使用以下编译命令对测试目标函数启用O-LLVM完整保护:
1 | ../build/bin/clang -m32 target.c -o target_flat -mllvm -bcf -mllvm -boguscf-prob=100 -mllvm -boguscf-loop=1 -mllvm -sub -mllvm -fla -mllvm -perFLA=100 |
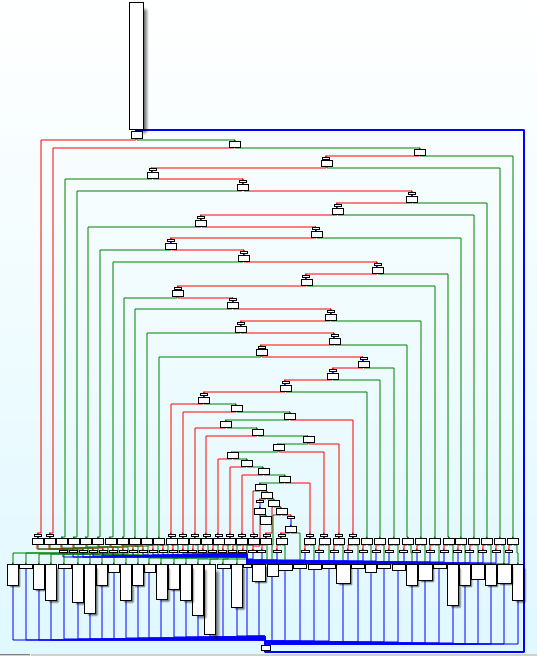
通过IDA查看被保护的函数代码,可以看到以下控制流图:
!!!
!!!
可以看出很重要的一点,通过保护方式叠加似乎明显地提高了代码的混淆程度,因为“不透明谓词”可以通过“指令替换”来转换实现,而“控制流平坦化”又会被应用于“伪造控制流”保护后的代码。从上面的截图中可以看到更加庞杂的相关块。